
 老贱丶
老贱丶
? ?Hadoop并没有使用JAVA的序列化,而是引入了自己实的序列化系统,package?org.apache.hadoop.io这个包中定义了大量的可序列化对象,这些对象都实现了Writable接口,Writable接口是序列化对象的一个通用接口.
?
我们来看下Writable?接口的定义。
?
view?sourceprint?1publicinterfaceWritable{2voidwrite(DataOutput?out)?throwsIOException;3voidreadFields(DataInput?in)?throwsIOException;4}
?
?
Writable接口抽象了两个序列化的方法Write和ReadFields,分别对应了序列化和反序列化,参数DataOutPut?为java.io包内的IO类,Writable接口只是对象序列化的一个简单声明。
?
? WriteCompareable接口
?
? ? WriteCompareable接口是Wirtable接口的二次封装,提供了compareTo(T?o)方法,用于序列化对象的比较的比较,下面是io包简单的类图关系。
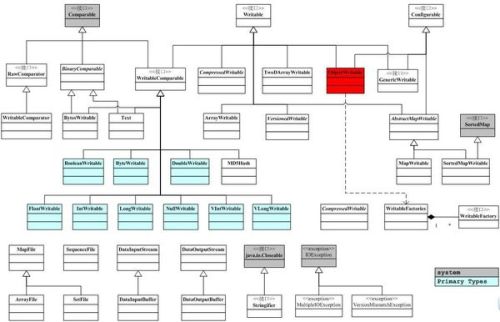
来源:商业智能和数据仓库爱好者
提供,,,商业智能和云计算。。。。。。。陪,训。。包含hadoop
表示完全不懂
