
 那晚越女说我?
那晚越女说我?
作为一个开源云计算平台,Hadoop正受到越来越多开发者的重视。从企业的角度来说,日益增长的信息已经很难存储在标准关系型数据库甚至数据仓库 中。这些问题提到了一些在实践中已存在多年的难题。例如:怎样查询一个十亿行的表?怎样跨越数据中心所有服务器上的所有日志来运行一个查询?更为复杂的问 题是,大量需要处理的数据是非结构化或者半结构化的,这就更难查询了。
当数据以这种数量存在时,一个处理局限是要花费很多的时间来移动数据,Apache Hadoop 的出现解决了这些问题,用其独一无二的方法将工作移到数据,而不是相反的移动。
Yahoo公司Hadoop应用架构师——Milind Bhandarkar日前在接受采访时,重点谈到了Hadoop跟传统的计算模式的区别。
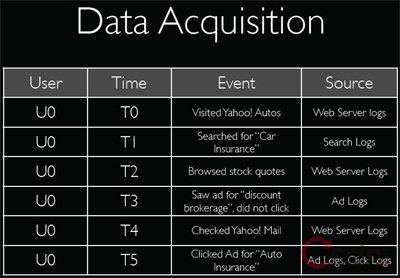
Yahoo目前有超过38000台服务器,有超过4000个以上的服务器集群,数据总量达到了170PB,每日的数据增量在10TB以上。
Yahoo的Hadoop应用包含有搜索、日志处理(Analytics, Reporting, Buzz)、用户建模、内容优化,垃圾邮件过滤器以及广告计算等。
如何利用Hadoop对海量数据进行优化处理是Yahoo正在致力于工作的内容。以网络分析为例,Yahoo目前有超过100亿个网页,1PB的网页数据内容,2万亿条链接,每日面临这300TB的数据输出。
“在应用Hadoop前,实施这一过程我们大概需要1个月的时间,但应用后仅需要1周时间”Milind Bhandarkar表示。
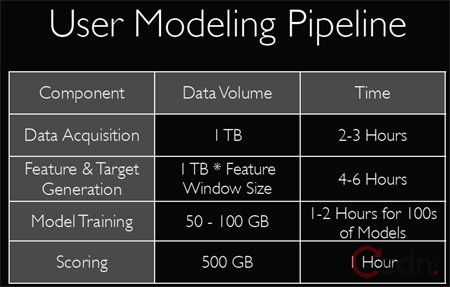
Hadoop在Yahoo的一些实际应用案例
“再以Yahoo搜索为例,我们的服务器上保留有用户三年来的搜索记录,这个数据是由超过10TB的自然语言文本库所组成”,“如果数据重整,我们在应用Hadoop前需要1个月的时间进行处理,而在有了Hadoop后仅仅需要30分钟。”
但与此同时Milind Bhandarkar也指出,Hadoop也非万能,它采用Java实现,Java的IO处理虽然没有性能瓶颈,但是对于CPU密集型的任务是一个麻烦,因此,有些算法效率不会提高很多。
