
 aoplge
aoplge
tinker有个非常大的亮点就是自研发了一套dex diff、patch相关算法。本篇文章主要目的就是分析该算法。当然值得注意的是,分析的前提就是需要对dex文件的格式要有一定的认识,否则的话可能会一脸懵逼态。
所以,本文会先对dex文件格式做一个简单的分析,也会做一些简单的实验,最后进入到dex diff,patch算法部分。
首先简单了解下Dex文件,大家在反编译的时候,都清楚apk中会包含一个或者多个*.dex文件,该文件中存储了我们编写的代码,一般情况下我们还会通过工具转化为jar,然后通过一些工具反编译查看。
jar文件大家应该都清楚,类似于class文件的压缩包,一般情况下,我们直接解压就可以看到一个个class文件。而dex文件我们无法通过解压获取内部的一个个class文件,说明dex文件拥有自己特定的格式:
dex对Java类文件重新排列,将所有JAVA类文件中的常量池分解,消除其中的冗余信息,重新组合形成一个常量池,所有的类文件共享同一个常量池,使得相同的字符串、常量在DEX文件中只出现一次,从而减小了文件的体积。
接下来我们看看dex文件的内部结构到底是什么样子。
分析一个文件的组成,最好自己编写一个最简单的dex文件来分析。
首先我们编写一个类Hello.java:
public class Hello{
public static void main(String[] args){
System.out.println("hello dex!");
}
}
然后进行编译:
javac -source 1.7 -target 1.7 Hello.java
最后通过dx工作将其转化为dex文件:
dx --dex --output=Hello.dex Hello.class
dx路径在Android-sdk/build-tools/版本号/dx下,如果无法识别dx命令,记得将该路径放到path下,或者使用绝对路径。
这样我们就得到了一个非常简单的dex文件。
首先展示一张dex文件的大致的内部结构图:
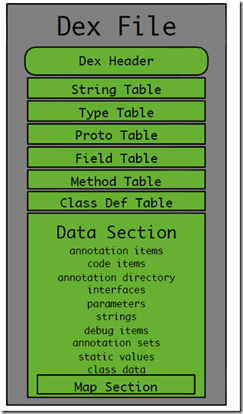
当然,单纯从一张图来说明肯定是远远不够的,因为我们后续要研究diff,patch算法,理论上我们应该要知道更多的细节,甚至要细致到:一个dex文件的每个字节表示的是什么内容。
对于一个类似于二进制的文件,最好的办法肯定不是靠记忆,好在有这么一个软件可以帮助我们的分析:
- 软件名称:010 Editor
下载完成安装后,打开我们的dex文件,会引导你安装dex文件的解析模板。
最终打开效果图如下:
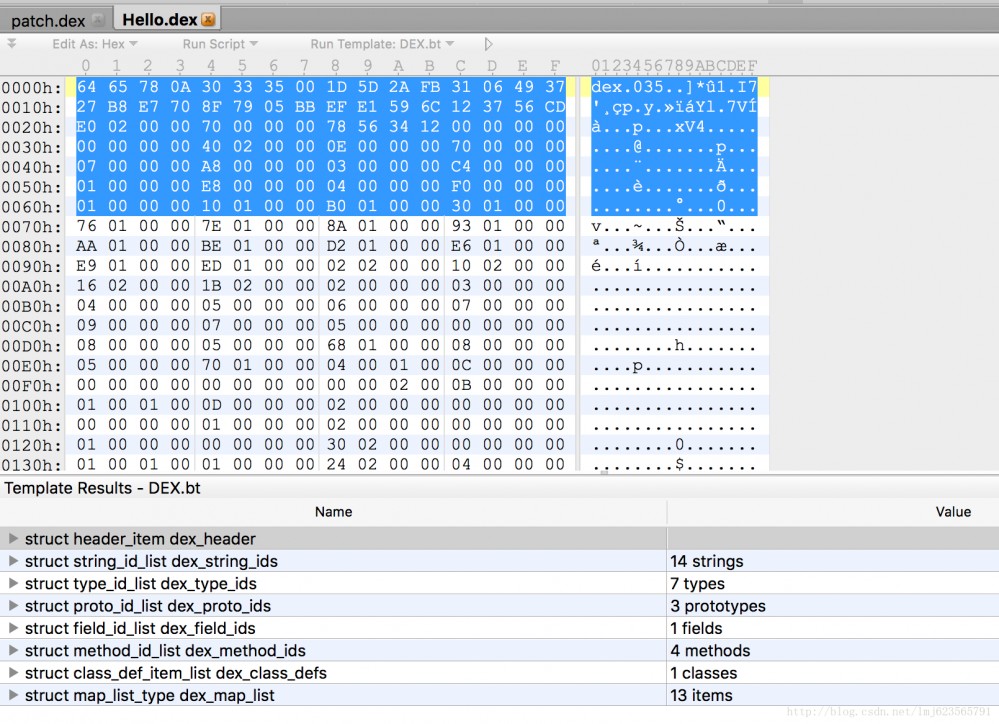
上面部分代表了dex文件的内容(16进制的方式展示),下面部分展示了dex文件的各个区域,你可以通过点击下面部分,来查看其对应的内容区域以及内容。
当然这里也非常建议,阅读一些专门的文章来加深对dex文件的理解:
- DEX文件格式分析
- Android逆向之旅—解析编译之后的Dex文件格式
本文也仅会对dex文件做简单的格式分析。
dex_header
首先我们队dex_header做一个大致的分析,header中包含如下字段:
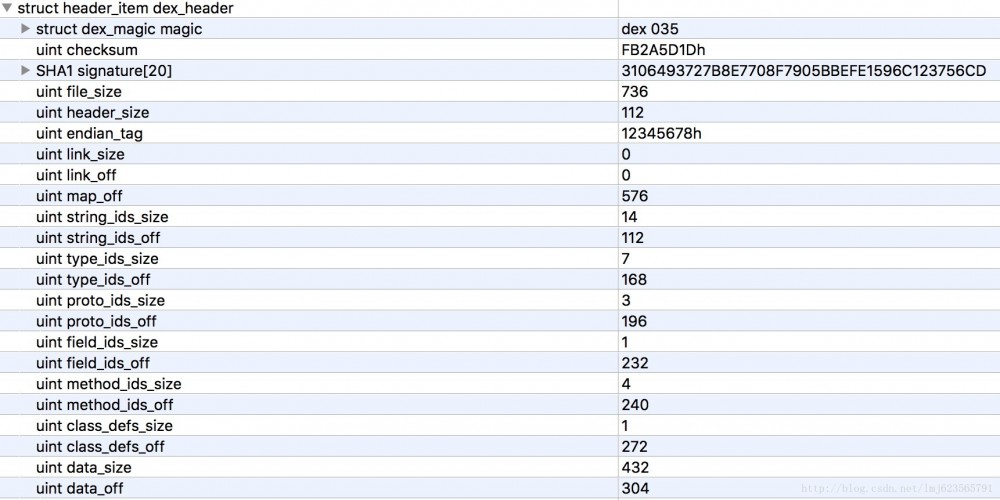
首先我们猜测下header的作用,可以看到起包含了一些校验相关的字段,和整个dex文件大致区块的分布(off都为偏移量)。
这样的好处就是,当虚拟机读取dex文件时,只需要读取出header部分,就可以知道dex文件的大致区块分布了;并且可以检验出该文件格式是否正确、文件是否被篡改等。
- 能够证明该文件是dex文件
- checksum和signature主要用于校验文件的完整性
- file_size为dex文件的大小
- head_size为头文件的大小
- endian_tag预设值为12345678,标识默认采用Little-Endian(自行搜索)。
剩下的几乎都是成对出现的size和off,大多代表各区块的包含的特定数据结构的数量和偏移量。例如:string_ids_off为112,指的是偏移量112开始为string_ids区域;string_ids_size为14,代表string_id_item的数量为14个。剩下的都类似就不介绍了。
结合010Editor可以看到各个区域包含的数据结构,以及对应的值,慢慢看就好了。
除了header还有个比较重要的部分是dex_map_list,首先看个图:
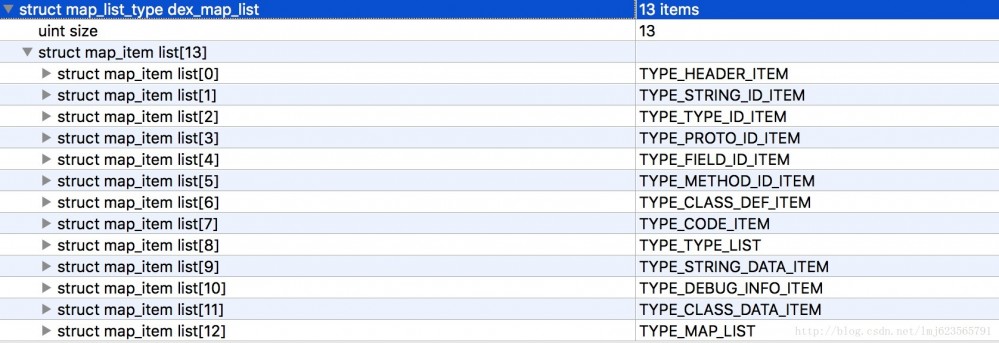
首先是map_item_list数量,接下来是每个map_item_list的描述。
map_item_list有什么用呢?
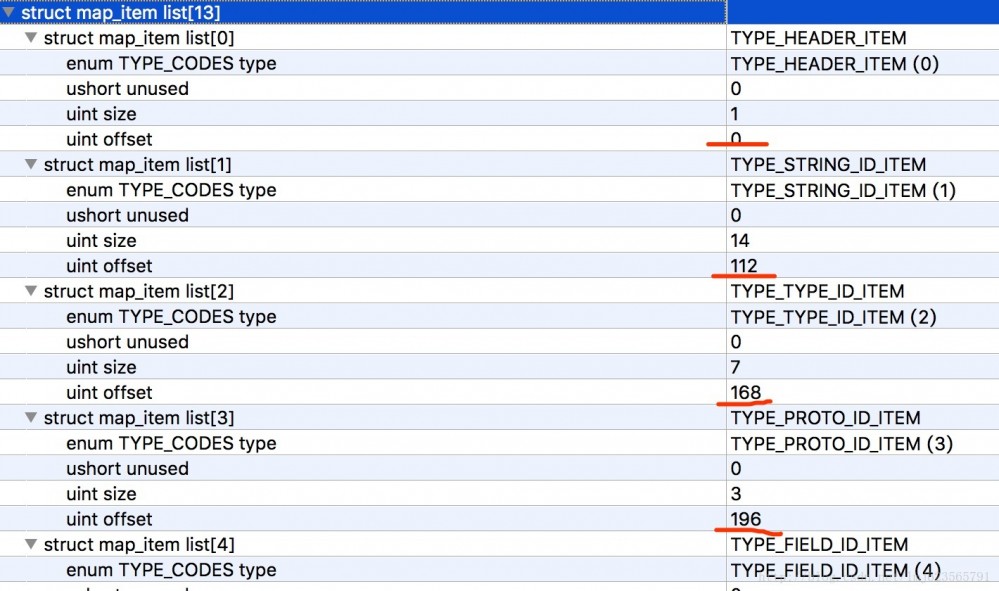
可以看到每个map_list_item包含一个枚举类型,一个2字节暂未使用的成员、一个size表明当前类型的个数,offset表明当前类型偏移量。
拿本例来说:
- 首先是TYPE_HEADER_ITEM类型,包含1个header(size=1),且偏移量为0。
- 接下来是TYPE_STRING_ID_ITEM,包含14个string_id_item(size=14),且偏移量为112(如果有印象,header的长度为112,紧跟着header)。
剩下的依次类推~~
这样的话,可以看出通过map_list,可以将一个完整的dex文件划分成固定的区域(本例为13),且知道每个区域的开始,以及该区域对应的数据格式的个数。
通过map_list找到各个区域的开始,每个区域都会对应特定的数据结构,通过010 Editor看就好了。
现在我们了解了dex的基本格式,接下来我们考虑下如何做dex diff 和 patch。
先要考虑的是我们有什么:
- old dex
- new dex
我们想要生成一个patch文件,该文件和old dex 通过patch算法还能生成new dex。
- 那么我们该如何做呢?
根据上文的分析,我们知道dex文件大致有3个部分(这里3个部分主要用于分析,勿较真):
- header
- 各个区域
- map list
header实际上是可以根据后面的数据确定其内容的,并且是定长112的;各个区域后面说;map list实际上可以做到定位到各个区域开始位置;
我们最终patch + old dex -> new dex;针对上述的3个部分,
- header我们可以不做处理,因为可以根据其他数据生成;
- map list这个东西,其实我们主要要的是各个区域的开始(offset)
- 知道了各个区域的offset后,在我们生成new dex的时候,我们就可以定位各个区域的开始和结束位置,那么只需要往各个区域写数据即可。
那么我们看看针对一个区域的diff,假设有个string区域,主要用于存储字符串:
old dex该区域的字符串有: Hello、World、zhy
new dex该区域的字符串有: Android、World、zhy
可以看出,针对该区域,我们删除了Hello,增加了Android。
那么patch中针对该区域可以如下记录:
“del Hello , add Android”(实际情况需要转化为二进制)。
想想应用中可以直接读取出old dex,即知道:
- 原来该区域包含:Hello、World、zhy
- patch中该区域包含:”del Hello , add Android”
那么,可以非常容易的计算出new dex中包含:
Android、World、zhy。
这样我们就完成了一个区域大致的diff和patch算法,其他各个区域的diff和patch和上述类似。
这样来看,是不是觉得这个diff和patch算法也没有那么的复杂,实际上tinker的做法与上述类似,实际情况可能要比上述描述要复杂一些,但是大体上是差不多的。
有了一个大致的算法概念之后,我们就可以去看源码了。
这里看代码实际上也是有技巧的,tinker的代码实际上蛮多的,往往你可以会陷在一堆的代码中。我们可以这么考虑,比如diff算法,输入参数为old dex 、new dex,输出为patch file。
那么肯定存在某个类,或者某个方法接受和输出上述参数。实际上该类为DexPatchGenerator:
diff的API使用代码为:
@Test
public void testDiff() throws IOException {
File oldFile = new File("Hello.dex");
File newFile = new File("Hello-World.dex");
File patchFile = new File("patch.dex");
DexPatchGenerator dexPatchGenerator
= new DexPatchGenerator(oldFile, newFile);
dexPatchGenerator.executeAndSaveTo(patchFile);
} 