怪我咯45804273
怪我咯45804273
当我们了解到urllib的基本用法之后,发现其中确实有很多不方便的地方,比如处理网页验证和Cookies的时候需要写Opener 和Handler来处理。今天给大家介绍更加强大requests库抓取简单的二进制数据:
1.下面以GitHub的站点图标来来一下:
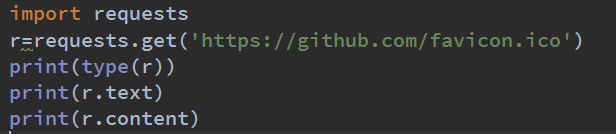
这边利用requests抓取站点图标,打印了Response的两个属性:text和content.运行结果如图:
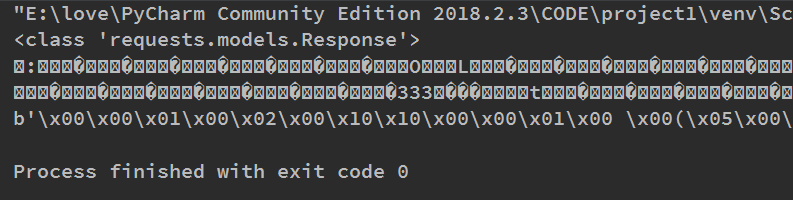
可以注意到,前者出现了乱码,后面出现了以b开头的数据(byte类型的数据)。因为图片是二进制数据,前面在打印的时候直接转换成str类型变成字符串,所以出现了乱码,而后面就是他的二进制数据信息。
2.下面我们就来保存刚才提取的图片:

这里在open()方法中传入了二个参数,分别是 :文件名,二进制形式写入。
3.运行结束后我们会发现在我们的文件夹中出现了favicon.ico的图标(同样的音频和视频文件也可以用这种方式获取):