
 肉包子一个一块
肉包子一个一块
1、保存网页
在浏览器中访问目标网页,执行菜单“文件”→“另存为”,文件类型选择“网页,全部”。
2、用WPS文字打开html文件
执行“文件”→“打开”,文件类型选择“网页文件”或“所有文件”,以打开刚才下载得到的《[征稿八]怎样用WPS制作PDF》html文件。
3、去掉不需要的部分
注:表格形式出现的正文,可以选中后执行“表格”→“转换”→“表格转换为文本”去除表格外框。
4、最后另存为WPS文档或WORD文档即可。
HTML怎么导出生成word文档
1、保存网页
在浏览器中访问目标网页,执行菜单“文件”→“另存为”,文件类型选择“网页,全部”。
2、用WPS文字打开html文件
执行“文件”→“打开”,文件类型选择“网页文件”或“所有文件”,以打开刚才下载得到的《[征稿八]怎样用WPS制作PDF》html文件。
3、去掉不需要的部分
注:表格形式出现的正文,可以选中后执行“表格”→“转换”→“表格转换为文本”去除表格外框。
4、最后另存为WPS文档或WORD文档即可。

如何将WORD文档导出为html文件?谢谢
另存为 全部 文件名.htm
html 导出 word
打开 HTML 文件,点击菜单栏 文件→使用 Microsoft Office Word 编辑,之后系统会自动打开 Word 并显示HTML文件的内容,这是保存即可。
如果找不到“使用 Microsoft Office Word 编辑”的话,点击菜单栏 工具→Internet 选项→程序→ HTML 编辑器 → Microsoft Office Word → 确定。
html导出word有哪些好的解决方案
1、实现富文本中样式代码的分离;
2、保留CSS样式;
其实以上两个步骤是相互矛盾的处理过程,无法通过Jacob或POI组件加正则表达式过滤解决,于是进行了以下步骤的实验:
1、首先创建了一个空白word文档,格式(office 2003格式或office 2007格式)不限;
2、将word格式保存为html格式,通过Edit Plus打开,发现代码中使用了office的命名空间,同时使用了office命名空间的标签定义了CSS样式,自己测试了一下,将生成的html文件头和尾拷贝出来:代码如下:
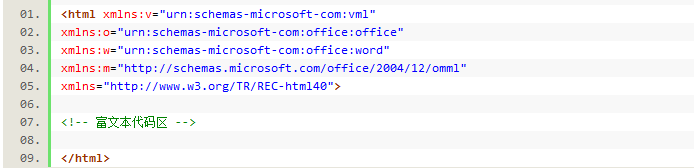
以上HTML头是office的命名空间定义。
3、将使用富文本代码粘贴到红色标识的<!-- 富文本代码区 -->中,并以doc或docx格式保存文件;
4、大功告成,打开文件时,Word将会以“Web版视图”完美显示了富文本样式,成功解决了富文本代码中样式代码,并同时保留了格式;
目前研究的仅能保存文字,未处理有图片的代码,朋友们可以再研究一下带图片的富文本代码的转换;
网页上打开的WORD文档 保存在哪个文件夹里了?
你试一下再次选择打开,然后选择“另存为。。”,
这时弹出的对话框,就是你默认的保存位置,
在这个文件夹里面应该能找到你上次保存的东西,祝你好运
请教java html导出word如何实现
java将html导出word不用忘记<html></html>这对标签
//换页
<span style='font-size:16px;line-height:150%;font-family:"Times New Roman";
mso-fareast-font-family:宋体;mso-font-kerning:1px;mso-ansi-language:EN-US;
mso-fareast-language:ZH-CN;mso-bidi-language:AR-SA'><br clear=all style='mso-special-character:page-break;page-break-before:always'>
</span>
//换行
<p style='line-height:150%'><span style='font-size:16px;line-height:150%'><o:p> </o:p></span></p>
查看的话 打开word 视图——页面 就能看出看出效果
[java] view plain copy print?
ArrayList records = form.getRecords();//获取数据库数据
if(null!=records&&0!=records.size()){
//html拼接出word内容
String content="<html>";
for (int i = 0; i < records.size(); i++) {
Record record =(Record) records.get(i);
//从数据库中获得数据,将oracle中的clob数据类型转换成string类型
Method method = record.get("CONTENT").getClass().getMethod("getVendorObj",new Class[]{});
CLOB clob = (CLOB)method.invoke(record.get("CONTENT"));
String cx = clob.getSubString((long) 1, (int) clob.length());
String title= (String) record.get("TITLE");
//html拼接出word内容
content+="<div style=\"text-align: center\"><span style=\"font-size: 24px\"><span style=\"font-family: 黑体\">"+title+"<br /> <br /> </span></span></div>";
content+="<div style=\"text-align: left\"><span >"+cx+"<br /> <br /> </span></span></div>";
//插入分页符
content+="<span lang=EN-US style='font-size:16px;line-height:150%;mso-fareast-font-family:宋体;mso-font-kerning:1px;mso-ansi-language:EN-US;mso-fareast-language:ZH-CN;mso-bidi-language:AR-SA'><br clear=all style='page-break-before:always'></span>";
content+="<p class=MsoNormal style='line-height:150%'><span lang=EN-US style='font-size:16px;line-height:150%'><o:p> </o:p></span></p>";
}
content += "</html>";
byte b[] = content.getBytes();
ByteArrayInputStream bais = new ByteArrayInputStream(b);
POIFSFileSystem poifs = new POIFSFileSystem();
DirectoryEntry directory = poifs.getRoot();
DocumentEntry documentEntry = directory.createDocument("WordDocument", bais);
//输出文件
String name="导出知识";
response.reset();
response.setHeader("Content-Disposition",
"attachment;filename=" +
new String( (name + ".doc").getBytes(),
"iso-8859-1"));
response.setContentType("application/msword");
OutputStream ostream = response.getOutputStream();
//输出文件的话,new一个文件流
//FileOutputStream ostream = new FileOutputStream(path+ fileName);
poifs.writeFilesystem(ostream);
ostream.flush();
ostream.close();
bais.close();
java html导出成word文档 文本框怎么解决
两种方式:
1、纯Java,用POI来做
2、用JNA调用word接口,根据office api来做 第一种呢对于java开发来说相对简单,但是需要学POI,而且估计有些格式控制不好。第二种要学习JNA,而且需要边做变差word的office api。
转载请注明出处51数据库 » chtml导出word文档 HTML怎么导出生成word文档
