
 女暧男
女暧男
1.先打开一个文档,可以是txt、doc、docx,只要是word支持的皆可。
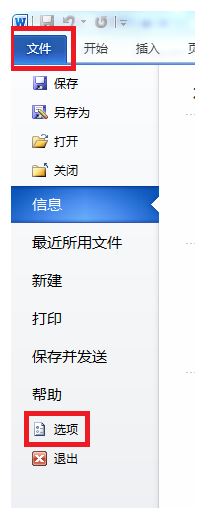
2.可以先查看下这个文档目前的编码方式,点击左上角的文件,然后选择选项。
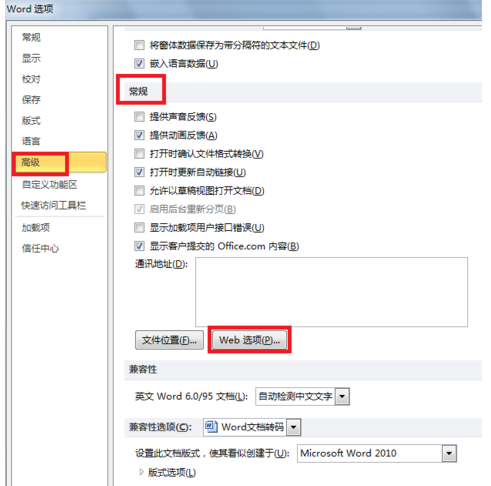
3.向下滚动到常规这一部分,然后点击Web选项。
4.选择编码,然后就会看到目前的编码方式,我们这边是GB2312。
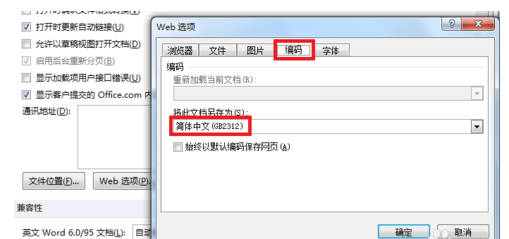
5.假设要将它转化为UTF-8的编码方式,那么这个时候点击另存为,跳出保存的弹框,然后点击工具选择Web选项。
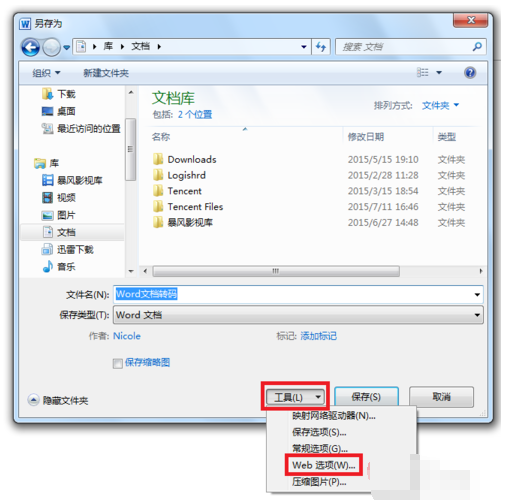
6.一样选择编码,将GB2312改成UTF-8,点击确定。
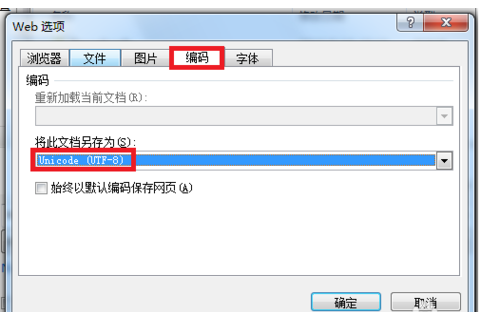
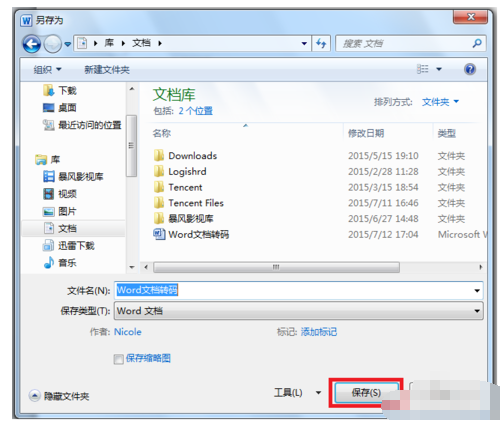
7.点击保存后,文档就被成功解码啦。
怎么把Word转成TXT-UTF-8格式
TXT是纯文本格式的文件,没有办法保存图片的,请LZ理解。可通过在word中“另存为”选项中选择“TXT”类型保存。所有的文字都将被保存,图片和大部分的排版格式将丢失。
如何将文本文档以utf-8编码格式保存
打开txt文件。
右上角 文件——另存为
将编码改为UTF-8 就行了。
IE9浏览器怎么设置编码UTF-8?
有两种方法可以为IE9浏览器设置编码UTF-8,方法如下:
①打开IE9浏览器,按ALT键,选择查看->编码,将编码GB2312设置为UTF8。建议一般不要设置为UTF-8,避免出现乱码。
②打开ie浏览器后,选择【工具】-->【属性】-->【高级】,选择“总是以utf-8”显示。
这样就将IE9浏览器的编码设置为UTF-8。
如何将word文件转换成手机短信
直接把word文件转化为文本文件,之后再转化为手机短信文件。
手机短信保存成WORD文件
1、直接把手机短信文件的后缀改为txt或者doc(直接改为doc文件阅读更加方便)
2、然后用鼠标在文件上点右键,选择打开方式,选择用word打开。
3、打开doc文件时,会自动默认使用Unicode(UTF-8)编码打开,直接按确定打开就行了。
utf8编码改为gbk后,网站字体全部加粗了,是为什么?
编码UNICODE,GBK,UTF-8的区别详解
简单来说,unicode,gbk和大五码就是编码的值,而utf-8,uft-16之类就是这个值的表现形式.而前面那三种编码是一兼容的,同一个汉字,那三个码值是完全不一样的.如"汉"的uncode值与gbk就是不一样的,假设uncode为a040,gbk为b030,而uft-8码,就是把那个值表现的形式.utf-8码完全只针对uncode来组织的,如果GBK要转UTF-8必须先转uncode码,再转utf-8就OK了.
详细的就见下面转的这篇文章.
谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
这是一篇程序员写给程序员的趣味读物。所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级。整理这篇文章的动机是两个问题:
问题一:
使用Windows记事本的“另存为”,可以在GBK、Unicode、Unicode big endian和UTF-8这几种编码方式间相互转换。同样是txt文件,Windows是怎样识别编码方式的呢?
我很早前就发现Unicode、Unicode big endian和UTF-8编码的txt文件的开头会多出几个字节,分别是FF、 FE(Unicode),FE、FF(Unicode big endian),EF、BB、BF(UTF-8)。但这些标记是基于什么标准呢?
问题二:
最近在网上看到一个ConvertUTF.c,实现了UTF-32、UTF-16和UTF-8这三种编码方式的相互转换。对于Unicode(UCS2)、 GBK、UTF-8这些编码方式,我原来就了解。但这个程序让我有些糊涂,想不起来UTF-16和UCS2有什么关系。
查了查相关资料,总算将这些问题弄清楚了,顺带也了解了一些Unicode的细节。写成一篇文章,送给有过类似疑问的朋友。本文在写作时尽量做到通俗易懂,但要求读者知道什么是字节,什么是十六进制。
1、字符编码、内码,顺带介绍汉字编码
字符必须编码后才能被计算机处理。计算机使用的缺省编码方式就是计算机的内码。早期的计算机使用7位的ASCII编码,为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。
从 ASCII、GB2312到GBK,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK都属于双字节字符集 (DBCS)。
2000 年的GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。从汉字字汇上说,GB18030在GB13000.1的20902个汉字的基础上增加了CJK扩展A的6582个汉字(Unicode码 0x3400-0x4db5),一共收录了27484个汉字。
CJK就是中日韩的意思。Unicode为了节省码位,将中日韩三国语言中的文字统一编码。GB13000.1就是ISO/IEC 10646-1的中文版,相当于Unicode 1.1。
GB18030 的编码采用单字节、双字节和4字节方案。其中单字节、双字节和GBK是完全兼容的。4字节编码的码位就是收录了CJK扩展A的6582个汉字。例如:UCS的0x3400在GB18030中的编码应该是8139EF30,UCS的0x3401在GB18030中的编码应该是8139EF31。
微软提供了GB18030的升级包,但这个升级包只是提供了一套支持CJK扩展A的6582个汉字的新字体:新宋体-18030,并不改变内码。Windows 的内码仍然是GBK。
这里还有一些细节:
GB2312的原文还是区位码,从区位码到内码,需要在高字节和低字节上分别加上A0。
对于任何字符编码,编码单元的顺序是由编码方案指定的,与endian无关。例如GBK的编码单元是字节,用两个字节表示一个汉字。这两个字节的顺序是固定的,不受CPU字节序的影响。UTF-16的编码单元是word(双字节),word之间的顺序是编码方案指定的,word内部的字节排列才会受到 endian的影响。后面还会介绍UTF-16。
GB2312的两个字节的最高位都是1。但符合这个条件的码位只有 128*128=16384个。所以GBK和GB18030的低字节最高位都可能不是1。不过这不影响DBCS字符流的解析:在读取DBCS字符流时,只要遇到高位为1的字节,就可以将下两个字节作为一个双字节编码,而不用管低字节的高位是什么。
2、Unicode、UCS和UTF
前面提到从ASCII、GB2312、GBK到GB18030的编码方法是向下兼容的。而Unicode只与ASCII兼容(更准确地说,是与ISO-8859-1兼容),与GB码不兼容。例如“汉”字的Unicode编码是6C49,而GB码是BABA。
Unicode 也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。
TXT文件怎样转换成UTF格式的?
1,打开“记事本”
2,“记事本”--文件--另存为----编码改为UTF-8格式(默认为ANSI编码)
UTF不是一中格式,是TXT的一种编码。用记事本打开TXT文件,点“文件——另存为”下面有文件名、保存类型和编码三栏,在编码那一栏里选择最下面的UTF-8就可以了。
转载请注明出处51数据库 » word怎么改utf8 如何将word改为utf-8编码
