
 撸道灰飞烟灭
撸道灰飞烟灭
一、如何用python安装woord2vector
gensim 用conda install gensim 与pip install gensim 安装是不同的提示C编译器会更快,windows下装了MinGW 中文wiki处理gensim模块中有专门处理wiki语料的函数中文分词还是用的jieba因为wiki百科有繁体,简繁体转换用了 还有最开始程序运行有问题,发现了自己python的一个坏习惯,应该把程序写成函数[python] view plain copyif __name__ == '__main__': my_function() 这样子python import这个文件就不会发生问题[python] view plain copy# -*- coding: utf-8 -*- from gensim.corpora import WikiCorpus import jieba from langconv import * _author__ = 'Lust' # read the wiki.xml.bz2 # transform it to simplified Chinese (use langconv) # Chinese text segmentation(use jieba) # save it as txt def my_function(): space = " " i = 0 l = [] a = '..//data//zhwiki-latest-pages-articles.xml.bz2' f = open('..//data//reduce_zhiwiki.txt', 'w') wiki = WikiCorpus(a, lemmatize=False, dictionary={}) # texts = wiki.get_texts() for text in wiki.get_texts(): for temp_sentence in text: temp_sentence = Converter('zh-hans').convert(temp_sentence.decode('utf-8')) temp_sentence = temp_sentence.encode('utf-8') seg_list = list(jieba.cut(temp_sentence)) # for temp_term in temp_sentence: for temp_term in seg_list: l.append(temp_term.encode('utf-8')) f.write(space.join(l) + "\n") l = [] i = i + 1 print "Saved " + str(i) + " articles" # limit number of wikis if (i == 100): break f.close() if __name__ == '__main__': my_function() gensim中的word2vector超级简单,一个函数的事情。
唯一要注意的是workers=multiprocessing.cpu_count()-4,如果不-4,win10会蓝屏,因为CPU总是100%,把电脑累蓝了?[python] view plain copy# -*- coding: utf-8 -*- from gensim.models import Word2Vec from gensim.models.word2vec import LineSentence import multiprocessing _author__ = 'Lust' # read the txt # word2vec it # save it as model and vector def my_function(): a = open('..//data//zhiwiki_news.txt', 'r') f_1 = open('..//result//zhiwiki_news.model', 'w') f_2 = open('..//result//zhiwiki_news.vector', 'w') model = Word2Vec(LineSentence(a), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count()-4) model.save(f_1) model.save_word2vec_format(f_2, binary=False) if __name__ == '__main__': my_function() 使用训练好的模型[python] view plain copy# -*- coding: utf-8 -*- import gensim _author__ = 'Lust' # read the news # Chinese text segmentation(use jieba) # add it to zhiwiki_news def my_function(): model = gensim.models.Word2Vec.load_word2vec_format("wiki.en.text.vector", binary=False) model.most_similar("man") model.similarity("woman", "girl") if __name__ == '__main__': my_function()。
二、请解释两行c++代码
首先分析一下这两个typedef定义的类型,这个类型比较复杂,解释如下:
1、vobject是一个动态数组,数组中的每个元素都是object类型的指针,可以看做是 object* 类型的一维数组。
2、vvobject也是一个动态数组,数组中的每个元素都是vobject*类型(也就是说,数组中每个元素都是一个一维数组的指针),所以vvobject就可以看做是一个object*类型的二维数组。
有了以上的分析,下面应该很好懂了。
vvobject *all; //也可以写成:vector<vector<object*>*> *all all就是一个指向object*类型的二维数组的指针。
那么现在再来看(*all)[0][0][0],很显然*all就是对指向二维数组的指针解引用,得到的就是一个二维数组,所以(*all)[0][0]就是一个数组元素,没错,就是object*类型。现在我们得到了一个指向object类型的指针,再对这个指针进行下标[0]操作,也就是说用这个指针加0,再解引用,即对该指针解引用,于是得到了object.
至于(*(*all)[0])[0],按照上面的分析,(*all)是一个二维数组,(*all)[0]是一个一维数组(一维数组就相当于一个指针),*(*all)[0]就是就是数组元素了(也就是object*),再加[0]就得到object.
上面的说明应该已经比较清楚,下面再附一段代码,说明下标操作符[0]的解引用:
int main()
{
int a = 77;
int *pa = &a;
printf("*pa:%d, pa[0]:%d",*pa, pa[0]);
}
运行结果:
*pa:77, pa[0]:77
三、word2vec 词向量怎么来的
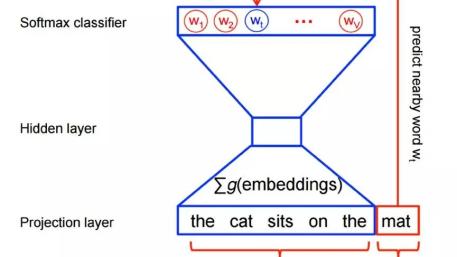
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。接下来,本文将从统计语言模型出发,尽可能详细地介绍word2vec工具背后的算法模型的来龙去脉。
详情:网页链接
四、word2vec和深度学习有什么关系
1、计算机视觉
ImageNet Classification with Deep Convolutional Neural Networks, Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton, NIPS 2012.
Learning Hierarchical Features for Scene Labeling, Clement Farabet, Camille Couprie, Laurent Najman and Yann LeCun, IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013.
Learning Convolutional Feature Hierarchies for Visual Recognition, Koray Kavukcuoglu, Pierre Sermanet, Y-Lan Boureau, Karol Gregor, Micha?l Mathieu and Yann LeCun, Advances in Neural Information Processing Systems (NIPS 2010), 23, 2010.
2、语音识别
微软研究人员通过与hintion合作,首先将RBM和DBN引入到语音识别声学模型训练中,并且在大词汇量语音识别系统中获得巨大成功,使得语音识别的错误率相对减低30%。但是,DNN还没有有效的并行快速算法,很多研究机构都是在利用大规模数据语料通过GPU平台提高DNN声学模型的训练效率。
在国际上,IBM、google等公司都快速进行了DNN语音识别的研究,并且速度飞快。
国内方面,阿里巴巴,科大讯飞、百度、中科院自动化所等公司或研究单位,也在进行深度学习在语音识别上的研究。
3、自然语言处理等其他领域
很多机构在开展研究,2013年Tomas Mikolov,Kai Chen,Greg Corrado,Jeffrey Dean发表论文Efficient Estimation of Word Representations in Vector Space建立word2vector模型,与传统的词袋模型(bag of words)相比,word2vector能够更好地表达语法信息。 深度学习在自然语言处理等领域主要应用于机器翻译以及语义挖掘等方面。
转载请注明出处51数据库 » word2vector源码分析
