
 _老基哥
_老基哥
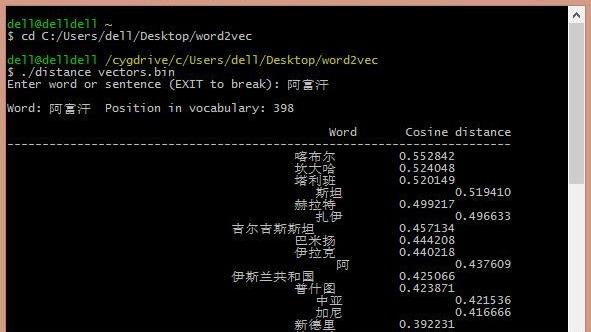
1.如何用 word2vec 计算两个句子之间的相似度
FC——文件比较命令 1.功能:比较文件的异同,并列出差异处。
2.类型:外部命令 3.格式:FC[盘符:][路径名]〈文件名〉[盘符:][路径名][文件名][/A][/B][/C][/N] 4.使用说明: (1)选用/A参数,为ASCII码比较模式; (2)选用/B参数,为二进制比较模式; (3)选用/C参数,将大小写字符看成是相同的字符。 (4)选用/N参数,在ASCII码比较方式下,显示相异处的行号。
不好意思,我还没有达到那个层次,只是dos学的时候比较认真一点,余弦定理的不会做。
2.如何通过词向量技术来计算2个文档的相似度
最近正好组内做了一个文档相似度的分享。
决定回答一发。 首先,如果不局限于NN的方法,可以用BOW+tf-idf+LSI/LDA的体系搞定,也就是俗称的01或one hot representation。
其次,如果楼主指定了必须用流行的NN,俗称word-embedding的方法,当然首推word2vec(虽然不算是DNN)。然后得到了word2vec的词向量后,可以通过简单加权/tag加权/tf-idf加权等方式得到文档向量。
这算是一种方法。当然,加权之前一般应该先干掉stop word,词聚类处理一下。
还有,doc2vec中的paragraph vector也属于直接得到doc向量的方法。特点就是修改了word2vec中的cbow和skip-gram模型。
依据论文《Distributed Representations of Sentences and Documents》(ICML 2014)。 还有一种根据句法树加权的方式,是ICML2011提出的,见论文《Parsing Natural Scenes and Natural Language with Recursive Neural Networks》,后续也有多个改编的版本。
当然,得到词向量的方式不局限于word2vec,RNNLM和glove也能得到传说中高质量的词向量。 ICML2015的论文《From Word Embeddings To Document Distances, Kusner, Washington University》新提出一种计算doc相似度的方式,大致思路是将词之间的余弦距离作为ground distance,词频作为权重,在权重的约束条件下,求WMD的线性规划最优解。
最后,kaggle101中的一个word2vec题目的tutorial里作者如是说:他试了一下简单加权和各种加权,不管如何处理,效果还不如01,归其原因作者认为加权的方式丢失了最重要的句子结构信息(也可以说是词序信息),而doc2vec的方法则保存了这种信息。 在刚刚结束的ACL2015上,似乎很多人提到了glove的方法,其思想是挖掘词共现信息的内在含义,据说是基于全局统计的方法(LSI为代表)与基于局部预测的方法(word2vec为代表)的折衷,而且输出的词向量在词聚类任务上干掉了word2vec的结果,也可以看看。
《GloVe: Global Vectors forWord Representation》。
3.如何计算两个文档的相似度
如果不局限于NN的方法:他试了一下简单加权和各种加权, Washington University》新提出一种计算doc相似度的方式,见论文《Parsing Natural Scenes and Natural Language with Recursive Neural Networks》。
特点就是修改了word2vec中的cbow和skip-gram模型,俗称word-embedding的方法,kaggle101中的一个word2vec题目的tutorial里作者如是说,据说是基于全局统计的方法(LSI为代表)与基于局部预测的方法(word2vec为代表)的折衷 最近正好组内做了一个文档相似度的分享,效果还不如01,doc2vec中的paragraph vector也属于直接得到doc向量的方法,求WMD的线性规划最优解。
4.如何通过词向量技术来计算2个文档的相似度
最近正好组内做了一个文档相似度的分享。决定回答一发。
首先,如果不局限于NN的方法,可以用BOW+tf-idf+LSI/LDA的体系搞定,也就是俗称的01或one hot representation。
其次,如果楼主指定了必须用流行的NN,俗称word-embedding的方法,当然首推word2vec(虽然不算是DNN)。然后得到了word2vec的词向量后,可以通过简单加权/tag加权/tf-idf加权等方式得到文档向量。这算是一种方法。当然,加权之前一般应该先干掉stop word,词聚类处理一下。
还有,doc2vec中的paragraph vector也属于直接得到doc向量的方法。特点就是修改了word2vec中的cbow和skip-gram模型。依据论文《Distributed Representations of Sentences and Documents》(ICML 2014)。
还有一种根据句法树加权的方式,是ICML2011提出的,见论文《Parsing Natural Scenes and Natural Language with Recursive Neural Networks》,后续也有多个改编的版本。
当然,得到词向量的方式不局限于word2vec,RNNLM和glove也能得到传说中高质量的词向量。
ICML2015的论文《From Word Embeddings To Document Distances, Kusner, Washington University》新提出一种计算doc相似度的方式,大致思路是将词之间的余弦距离作为ground distance,词频作为权重,在权重的约束条件下,求WMD的线性规划最优解。
最后,kaggle101中的一个word2vec题目的tutorial里作者如是说:他试了一下简单加权和各种加权,不管如何处理,效果还不如01,归其原因作者认为加权的方式丢失了最重要的句子结构信息(也可以说是词序信息),而doc2vec的方法则保存了这种信息。
在刚刚结束的ACL2015上,似乎很多人提到了glove的方法,其思想是挖掘词共现信息的内在含义,据说是基于全局统计的方法(LSI为代表)与基于局部预测的方法(word2vec为代表)的折衷,而且输出的词向量在词聚类任务上干掉了word2vec的结果,也可以看看。《GloVe: Global Vectors forWord Representation》
5.求关于文档相似度
对于文档/文本相似度的判定采取的主要算法有3种:
1、最长公共子串算法(Longest-common-subsequence , LCS算法)。LCS算法就是求两个字符串的公共子串的最大可能长度。
2、余弦定理 (向量空间算法)。这是利用余弦定理和广义Jaccard系数来计算文本相似度。
3、距离编辑算法(Levenshtein Distance,LD算法)。距离编辑的定义是将字符串A转换为字符串B所用的最少字符操作数。
有用“距离编辑算法”写了毕业论文和代码,某宝上搜索“文档相似度检测系统 代码”可以买到
6.Word2vec的词聚类结果与LDA的主题词聚类结果,有什么不同
所以Word2vec的一些比较精细的应用,LDA是做不了的。
比如:1)计算词的相似度。同样在电子产品这个主题下,“苹果”是更接近于“三星”还是“小米”?2)词的类比关系:vector(小米)- vector(苹果)+ vector(乔布斯)近似于 vector(雷军)。
3)计算文章的相似度。这个LDA也能做但是效果不好。
而用词向量,即使在文章topic接近的情况下,计算出的相似度也能体现相同、相似、相关的区别。反过来说,想用词向量的聚类去得到topic这一级别的信息也是很难的。
很有可能,“苹果”和“小米”被聚到了一类,而“乔布斯”和“雷军”则聚到另一类。这种差别,本质上说是因为Word2vec利用的是词与上下文的共现,而LDA利用的是词与文章之间的共现。
PS. 说起来,拿LDA和doc2vec比较才比较合理啊~~。
转载请注明出处51数据库 » word2vec计算相似度
