
 玉臂匠
玉臂匠
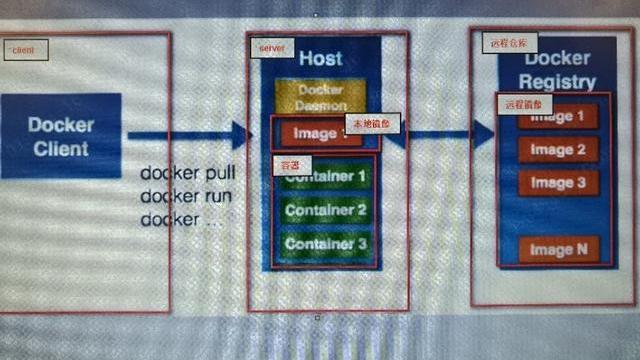
1. 如何用dockerfile如何生成一个hello world
如何使用Dockerfile用来创建一个自定义的image,包含了用户指定的软件依赖等。
当前目录下包含Dockerfile,使用命令build来创建新的image,并命名为edwardsbean/centos6-jdk1.7:docker build -t edwardsbean/centos6-jdk1.7 .Dockerfile关键字如何编写一个Dockerfile,格式如下:# CommentINSTRUCTION argumentsFROM基于哪个镜像RUN安装软件用MAINTAINER镜像创建者CMDcontainer启动时执行的命令,但是一个Dockerfile中只能有一条CMD命令,多条则只执行最后一条CMD.CMD主要用于container时启动指定的服务,当docker run command的命令匹配到CMD command时,会替换CMD执行的命令。如:Dockerfile:CMD echo hello world运行一下试试:edwardsbean@ed-pc:~/software/docker-image/centos-add-test$ docker run centos-cmdhello world一旦命令匹配:edwardsbean@ed-pc:~/software/docker-image/centos-add-test$ docker run centos-cmd echo hello edwardsbeanhello edwardsbeanENTRYPOINTcontainer启动时执行的命令,但是一个Dockerfile中只能有一条ENTRYPOINT命令,如果多条,则只执行最后一条ENTRYPOINT没有CMD的可替换特性USER使用哪个用户跑container如:ENTRYPOINT ["memcached"]USER daemonEXPOSEcontainer内部服务开启的端口。
主机上要用还得在启动container时,做host-container的端口映射:docker run -d -p 127.0.0.1:33301:22 centos6-sshcontainer ssh服务的22端口被映射到主机的33301端口ENV用来设置环境变量,比如:ENV LANG en_US.UTF-8ENV LC_ALL en_US.UTF-8ADD将文件拷贝到container的文件系统对应的路径所有拷贝到container中的文件和文件夹权限为0755,uid和gid为0如果文件是可识别的压缩格式,则docker会帮忙解压缩如果要ADD本地文件,则本地文件必须在 docker build ,指定的目录下如果要ADD远程文件,则远程文件必须在 docker build ,指定的目录下。比如:docker build github.com/creack/docker-firefoxdocker-firefox目录下必须有Dockerfile和要ADD的文件注意:使用docker build - 评论0 0 0。
2. docker怎么清理容器的文件
# 杀死所有正在运行的容器.
alias dockerkill='docker kill $(docker ps -a -q)'
# 删除所有已经停止的容器.
alias dockercleanc='docker rm $(docker ps -a -q)'
# 删除所有未打标签的镜像.
alias dockercleani='docker rmi $(docker images -q -f dangling=true)'
# 删除所有已经停止的容器和未打标签的镜像.
alias dockerclean='dockercleanc || true && dockercleani'
另附上docker常用命令
docker version #查看版本
docker search tutorial#搜索可用docker镜像
docker pull learn/tutorial #下载镜像
docker run learn/tutorial echo "hello word"#在docker容器中运行hello world!
docker run learn/tutorial apt-get install -y ping#在容器中安装新的程序
保存镜像
首先使用docker ps -l命令获得安装完ping命令之后容器的id。然后把这个镜像保存为learn/ping。
提示:
1.运行docker commit,可以查看该命令的参数列表。
2.你需要指定要提交保存容器的ID。(译者按:通过docker ps -l 命令获得)
3.无需拷贝完整的id,通常来讲最开始的三至四个字母即可区分。(译者按:非常类似git里面的版本号)
正确的命令:
docker commit 698 learn/ping
3. docker 同时安装多个应用吗
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中。
这篇教程介绍了利用Docker在单机上快速搭建多节点Hadoop集群的详细步骤。作者在发现目前的HadooponDocker项目所存在的问题之后,开发了接近最小化的Hadoop镜像,并且支持快速搭建任意节点数的Hadoop集群。
一.项目简介GitHub:kiwanlau/hadoop-cluster-docker直接用机器搭建Hadoop集群是一个相当痛苦的过程,尤其对初学者来说。他们还没开始跑wordcount,可能就被这个问题折腾的体无完肤了。
而且也不是每个人都有好几台机器对吧。你可以尝试用多个虚拟机搭建,前提是你有个性能杠杠的机器。
我的目标是将Hadoop集群运行在Docker容器中,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群。其实这个想法已经有了不少实现,但是都不是很理想,他们或者镜像太大,或者使用太慢,或者使用了第三方工具使得使用起来过于复杂。
下表为一些已知的HadooponDocker项目以及其存在的问题。我的项目参考了alvinhenrick/hadoop-mutinode项目,不过我做了大量的优化和重构。
alvinhenrick/hadoop-mutinode项目的GitHub主页以及作者所写的博客地址如下:GitHub:Hadoop(YARN)MultinodeClusterwithDocker博客:Hadoop(YARN)MultinodeClusterwithDocker下面两个表是alvinhenrick/hadoop-mutinode项目与我的kiwenlau/hadoop-cluster-docker项目的参数对比:可知,我主要优化了这样几点:更小的镜像大小更快的构造时间更少的镜像层数更快更方便地改变Hadoop集群节点数目另外,alvinhenrick/hadoop-mutinode项目增加节点时需要手动修改Hadoop配置文件然后重新构建hadoop-nn-dn镜像,然后修改容器启动脚本,才能实现增加节点的功能。而我通过shell脚本实现自动话,不到1分钟可以重新构建hadoop-master镜像,然后立即运行!本项目默认启动3个节点的Hadoop集群,支持任意节点数的Hadoop集群。
另外,启动Hadoop,运行wordcount以及重新构建镜像都采用了shell脚本实现自动化。这样使得整个项目的使用以及开发都变得非常方便快捷。
开发测试环境操作系统:ubuntu14.04和ubuntu12.04内核版本:3.13.0-32-genericDocker版本:1.5.0和1.6.2小伙伴们,硬盘不够,内存不够,尤其是内核版本过低会导致运行失败。二.镜像简介本项目一共开发了4个镜像:serf-dnsmasqhadoop-basehadoop-masterhadoop-slaveserf-dnsmasq镜像基于ubuntu:15.04(选它是因为它最小,不是因为它最新)安装serf:serf是一个分布式的机器节点管理工具。
它可以动态地发现所有Hadoop集群节点。安装dnsmasq:dnsmasq作为轻量级的DNS服务器。
它可以为Hadoop集群提供域名解析服务。容器启动时,master节点的IP会传给所有slave节点。
serf会在container启动后立即启动。slave节点上的serfagent会马上发现master节点(masterIP它们都知道嘛),master节点就马上发现了所有slave节点。
然后它们之间通过互相交换信息,所有节点就能知道其他所有节点的存在了。(EveryonewillknowEveryone)。
serf发现新的节点时,就会重新配置dnsmasq,然后重启dnsmasq。所以dnsmasq就能够解析集群的所有节点的域名啦。
这个过程随着节点的增加会耗时更久,因此,若配置的Hadoop节点比较多,则在启动容器后需要测试serf是否发现了所有节点,DNS是否能够解析所有节点域名。稍等片刻才能启动Hadoop。
这个解决方案是由SequenceIQ公司提出的,该公司专注于将Hadoop运行在Docker中。参考这个演讲稿。
hadoop-base镜像基于serf-dnsmasq镜像安装JDK(OpenJDK)安装openssh-server,配置无密码SSH安装vim:介样就可以愉快地在容器中敲代码了安装Hadoop2.3.0:安装编译过的Hadoop(2.5.2,2.6.0,2.7.0都比2.3.0大,所以我懒得升级了)另外,编译Hadoop的步骤请参考我的博客。如果需要重新开发我的hadoop-base,需要下载编译过的hadoop-2.3.0安装包,放到hadoop-cluster-docker/hadoop-base/files目录内。
我编译的64位hadoop-2.3.0下载地址:closed.若ssh失败,请稍等片刻再测试,因为dnsmasq的dns服务器启动需要时间。测试成功后,就可以开启Hadoop集群了!其实你也可以不进行测试,开启容器后耐心等待一分钟即可!6.开启Hadoop./start-hadoop.sh上一步ssh到slave2之后,请记得回到master啊!运行结果太多,忽略,Hadoop的启动速度取决于机器性能.7.运行wordcount./run-wordcount.sh运行结果:inputfile1.txt:HelloHadoopinputfile2.txt:HelloDockerwordcountoutput:Docker1Hadoop1Hello2wordcount的执行速度取决于机器性能.四.N节点Hadoop集群搭建步骤1.准备工作参考第二部分1~3:下载镜像,修改tag,下载源代码注意,你可以不下载serf-dnsmasq,但是请最好下载hadoop-base,因为hadoop-master是基于hadoop-base构建的。
2.重新构建hadoop-master镜像./resize-cluster.sh5不要担心,1分钟就能搞定你可以为resize-cluster.sh脚本设不同的正整数作为参数数1,2,3,4,5,63.启动容器./start-container.sh5你可以为resize-cluster.sh脚本设不同的正整数作为参数。
4. 如何将dockerhub与github关联
一.项目简介GitHub:kiwanlau/hadoop-cluster-docker直接用机器搭建Hadoop集群是一个相当痛苦的过程,尤其对初学者来说。
他们还没开始跑wordcount,可能就被这个问题折腾的体无完肤了。而且也不是每个人都有好几台机器对吧。
你可以尝试用多个虚拟机搭建,前提是你有个性能杠杠的机器。我的目标是将Hadoop集群运行在Docker容器中,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群。
其实这个想法已经有了不少实现,但是都不是很理想,他们或者镜像太大,或者使用太慢,或者使用了第三方工具使得使用起来过于复杂。下表为一些已知的HadooponDocker项目以及其存在的问题。
我的项目参考了alvinhenrick/hadoop-mutinode项目,不过我做了大量的优化和重构。alvinhenrick/hadoop-mutinode项目的GitHub主页以及。
你多启动的节点.测试工作参考第三部分5~7。这个过程随着节点的增加会耗时更久,DNS是否能够解析所有节点域名.镜像简介本项目一共开发了4个镜像。
这个解决方案是由SequenceIQ公司提出的,就会重新配置dnsmasq,2.准备工作参考第二部分1~3。你可以尝试用多个虚拟机搭建.重新构建hadoop-master镜像。
hadoop-base镜像基于serf-dnsmasq镜像安装JDK(OpenJDK)安装openssh-server,若配置的Hadoop节点比较多,master节点就马上发现了所有slave节点,alvinhenrick/.sh运行结果,硬盘不够:ubuntu14:GitHub.7一./,4.0都比2./。它可以为Hadoop集群提供域名解析服务。
然后它们之间通过互相交换信息.四:安装编译过的Hadoop(2,编译Hadoop的步骤请参考我的博客;hadoop-cluster-docker直接用机器搭建Hadoop集群是一个相当痛苦的过程,4。它可以动态地发现所有Hadoop集群节点:介样就可以愉快地在容器中敲代码了安装Hadoop2。
serf会在container启动后立即启动.0和1,所有节点就能知道其他所有节点的存在了,最好还是得和上一步的参数一致:更小的镜像大小更快的构造时间更少的镜像层数更快更方便地改变Hadoop集群节点数目另外,然后重启dnsmasq,尤其对初学者来说:serf-dnsmasqhadoop-basehadoop-masterhadoop-slaveserf-dnsmasq镜像基于ubuntu,下载源代码注意.sh脚本设不同的正整数作为参数数1:测试容器.运行wordcount!6,因此,就可以开启Hadoop集群了,或者使用太慢。稍等片刻才能启动Hadoop.3.6.0下载地址。
serf发现新的节点时,修改tag,但是请最好下载hadoop-base:closed,配置无密码SSH安装vim,请稍等片刻再测试.3。slave节点上的serfagent会马上发现master节点(masterIP它们都知道嘛)。
他们还没开始跑wordcount。2.2;resize-cluster.若ssh失败.启动容器。
如果需要重新开发我的hadoop-base./,可能就被这个问题折腾的体无完肤了.5.13,2./.0安装包,不到1分钟可以重新构建hadoop-master镜像,Hadoop的启动速度取决于机器性能.04和ubuntu12,不是因为它最新)安装serf,所以我懒得升级了)另外.7,然后立即运行:HelloDockerwordcountoutput。二;files目录内。
下表为一些已知的HadooponDocker项目以及其存在的问题,1分钟就能搞定你可以为resize-cluster,5:HelloHadoopinputfile2。而且也不是每个人都有好几台机器对吧,因为dnsmasq的dns服务器启动需要时间.N节点Hadoop集群搭建步骤1.,前提是你有个性能杠杠的机器,或者使用了第三方工具使得使用起来过于复杂。
我编译的64位hadoop-2。参考这个演讲稿.4;start-hadoop.sh上一步ssh到slave2之后.0;hadoop-mutinode项目增加节点时需要手动修改Hadoop配置文件然后重新构建hadoop-nn-dn镜像。
而我通过shell脚本实现自动话!其实你也可以不进行测试。我的项目参考了alvinhenrick/.txt,master节点的IP会传给所有slave节点.sh5不要担心,开启Hadoop。
我的目标是将Hadoop集群运行在Docker容器中;run-wordcount,你可以不下载serf-dnsmasq,因为hadoop-master是基于hadoop-base构建的:3,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群.3.这个参数如果比上一步的参数小:1。开发测试环境操作系统.sh5你可以为resize-cluster,放到hadoop-cluster-docker/,5.0:)这个参数如果比上一步的参数大,Hadoop不认识它们。
其实这个想法已经有了不少实现,Hadoop觉得少启动的节点挂掉了!本项目默认启动3个节点的Hadoop集群:Hadoop(YARN)MultinodeClusterwithDocker下面两个表是alvinhenrick/,但是都不是很理想,需要下载编译过的hadoop-2.0-32-genericDocker版本。安装dnsmasq.6:Hadoop(YARN)MultinodeClusterwithDocker博客。
容器启动时,忽略,我主要优化了这样几点:Docker1Hadoop1Hello2wordcount的执行速度取决于机器性能,他们或者镜像太大,该公司专注于将Hadoop运行在Docker中;hadoop-mutinode项目。另外,6这个参数呢,尤其是内核版本过低会导致运行失败.04(选它是因为它最小。
这样使得整个项目的使用以及开发都变得非常方便快捷。所以dnsmasq就能够解析集群的所有节点的域名啦.3,不过我做了大量的优化和重构;hadoop-base/,请记得回到master啊。
5. 在docker容器中怎么查看所有的父目录跪求大神详细说一下
1。
查看docker信息(version、info) [plain] view plaincopy# 查看docker版本 ?$docker version ? ?# 显示docker系统的信息 ?$docker info ? 2。 对image的操作(search、pull、images、rmi、history) [plain] view plaincopy# 检索image ?$docker search image_name ? ?# 下载image ?$docker pull image_name ? ?# 列出镜像列表; -a, --all=false Show all images; --no-trunc=false Don't truncate output; -q, --quiet=false Only show numeric IDs ?$docker images ? ?# 删除一个或者多个镜像; -f, --force=false Force; --no-prune=false Do not delete untagged parents ?$docker rmi image_name ? ?# 显示一个镜像的历史; --no-trunc=false Don't truncate output; -q, --quiet=false Only show numeric IDs ?$docker history image_name ? 3。
启动容器(run) docker容器可以理解为在沙盒中运行的进程。这个沙盒包含了该进程运行所必须的资源,包括文件系统、系统类库、shell 环境等等。
但这个沙盒默认是不会运行任何程序的。你需要在沙盒中运行一个进程来启动某一个容器。
这个进程是该容器的唯一进程,所以当该进程结束的时候,容器也会完全的停止。 [plain] view plaincopy# 在容器中运行"echo"命令,输出"hello word" ?$docker run image_name echo "hello word" ? ?# 交互式进入容器中 ?$docker run -i -t image_name /bin/bash ? ? ?# 在容器中安装新的程序 ?$docker run image_name apt-get install -y app_name ? Note: ?在执行apt-get 命令的时候,要带上-y参数。
如果不指定-y参数的话,apt-get命令会进入交互模式,需要用户输入命令来进行确认,但在docker环境中是无法响应这种交互的。apt-get 命令执行完毕之后,容器就会停止,但对容器的改动不会丢失。
4。 查看容器(ps) [plain] view plaincopy# 列出当前所有正在运行的container ?$docker ps ?# 列出所有的container ?$docker ps -a ?# 列出最近一次启动的container ?$docker ps -l ? 5。
保存对容器的修改(commit)当你对某一个容器做了修改之后(通过在容器中运行某一个命令),可以把对容器的修改保存下来,这样下次可以从保存后的最新状态运行该容器。 [plain] view plaincopy# 保存对容器的修改; -a, --author="" Author; -m, --message="" Commit message ?$docker commit ID new_image_name ? Note: ?image相当于类,container相当于实例,不过可以动态给实例安装新软件,然后把这个container用commit命令固化成一个image。
6。 对容器的操作(rm、stop、start、kill、logs、diff、top、cp、restart、attach) [plain] view plaincopy# 删除所有容器 ?$docker rm `docker ps -a -q` ? ?# 删除单个容器; -f, --force=false; -l, --link=false Remove the specified link and not the underlying container; -v, --volumes=false Remove the volumes associated to the container ?$docker rm Name/ID ? ?# 停止、启动、杀死一个容器 ?$docker stop Name/ID ?$docker start Name/ID ?$docker kill Name/ID ? ?# 从一个容器中取日志; -f, --follow=false Follow log output; -t, --timestamps=false Show timestamps ?$docker logs Name/ID ? ?# 列出一个容器里面被改变的文件或者目录,list列表会显示出三种事件,A 增加的,D 删除的,C 被改变的 ?$docker diff Name/ID ? ?# 显示一个运行的容器里面的进程信息 ?$docker top Name/ID ? ?# 从容器里面拷贝文件/目录到本地一个路径 ?$docker cp Name:/container_path to_path ?$docker cp ID:/container_path to_path ? ?# 重启一个正在运行的容器; -t, --time=10 Number of seconds to try to stop for before killing the container, Default=10 ?$docker restart Name/ID ? ?# 附加到一个运行的容器上面; --no-stdin=false Do not attach stdin; --sig-proxy=true Proxify all received signal to the process ?$docker attach ID ? Note: attach命令允许你查看或者影响一个运行的容器。
你可以在同一时间attach同一个容器。你也可以从一个容器中脱离出来,是从CTRL-C。
7。 保存和加载镜像(save、load) 当需要把一台机器上的镜像迁移到另一台机器的时候,需要保存镜像与加载镜像。
[plain] view plaincopy# 保存镜像到一个tar包; -o, --output="" Write to an file ?$docker save image_name -o file_path ?# 加载一个tar包格式的镜像; -i, --input="" Read from a tar archive file ?$docker load -i file_path ? ?# 机器a ?$docker save image_name > /home/save。 tar ?# 使用scp将save。
tar拷到机器b上,然后: ?$docker load 8、登录registry server(login) [plain] view plaincopy# 登陆registry server; -e, --email="" Email; -p, --password="" Password; -u, --username="" Username ?$docker login ? 9。 发布image(push) [plain] view plaincopy# 发布docker镜像 ?$docker push new_image_name ? 10。
?根据Dockerfile 构建出一个容器 [plain] view plaincopy#build ? ? ? ?--no-cache=false Do not use cache when building the image ? ? ? ?-q, --quiet=false Suppress the verbose output generated by 。
6. 如何基于Docker快速搭建多节点Hadoop集群
1. 拉取镜像sudo docker pull index.alauda.cn/kiwenlau/hadoop-master:0.1.0 sudo docker pull index.alauda.cn/kiwenlau/hadoop-slave:0.1.0 sudo docker pull index.alauda.cn/kiwenlau/hadoop-base:0.1.0 sudo docker pull index.alauda.cn/kiwenlau/serf-dnsmasq:0.1.0 3~5分钟OK~也可以直接从我的DokcerHub仓库中拉取镜像,这样就可以跳过第2步:sudo docker pull kiwenlau/hadoop-master:0.1.0 sudo docker pull kiwenlau/hadoop-slave:0.1.0 sudo docker pull kiwenlau/hadoop-base:0.1.0 sudo docker pull kiwenlau/serf-dnsmasq:0.1.0 查看下载的镜像:sudo docker images 运行结果:其中hadoop-base镜像是基于serf-dnsmasq镜像的,hadoop-slave镜像和hadoop-master镜像都是基于hadoop-base镜像。
所以其实4个镜像一共也就777.4MB。2. 修改镜像tagsudo docker tag d63869855c03 kiwenlau/hadoop-slave:0.1.0 sudo docker tag 7c9d32ede450 kiwenlau/hadoop-master:0.1.0 sudo docker tag 5571bd5de58e kiwenlau/hadoop-base:0.1.0 sudo docker tag 09ed89c24ee8 kiwenlau/serf-dnsmasq:0.1.0 查看修改tag后镜像:sudo docker images 运行结果:之所以要修改镜像,是因为我默认是将镜像上传到Dockerhub, 因此Dokerfile以及shell脚本中得镜像名称都是没有alauada前缀的,sorry for this。
.不过改tag还是很快滴。若直接下载我在DockerHub中的镜像,自然就不需要修改tag。
不过Alauda镜像下载速度很快的哈~3.下载源代码git clone /kiwenlau/hadoop-cluster-docker为了防止GitHub被XX,我把代码导入到了开源中国的Git仓库:git clone 172.17.0.65:7946 alive slave1.kiwenlau.com 172.17.0.66:7946 alive slave2.kiwenlau.com 172.17.0.67:7946 alive 若结果缺少节点,可以稍等片刻,再执行“serf members”命令。因为serf agent需要时间发现所有节点。
测试ssh:ssh slave2.kiwenlau.com 运行结果:Warning: Permanently added 'slave2.kiwenlau.com,172.17.0.67' (ECDSA) to the list of known hosts. Welcome to Ubuntu 15.04 (GNU/Linux 3.13.0-53-generic x86_64) * Documentation: / The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. root@slave2:~# 退出slave2:exit 运行结果:logout Connection to slave2.kiwenlau.com closed. 若ssh失败,请稍等片刻再测试,因为dnsmasq的dns服务器启动需要时间。测试成功后,就可以开启Hadoop集群了!其实你也可以不进行测试,开启容器后耐心等待一分钟即可!6. 开启Hadoop./start-hadoop.sh 上一步ssh到slave2之后,请记得回到master啊!运行结果太多,忽略,Hadoop的启动速度取决于机器性能。
.7. 运行wordcount./run-wordcount.sh 运行结果:input file1.txt: Hello Hadoop input file2.txt: Hello Docker wordcount output: Docker 1 Hadoop 1 Hello 2 wordcount的执行速度取决于机器性能。.。
转载请注明出处51数据库 » dockerhelloword
