
 大飞小晶
大飞小晶
请试用用ABBYY_FineReader。
目前最新的版本是ABBYY finereader 12 professional 版,可以识别 100多种语言,还有部分计算机语言。有利器在手,我们当然要把它的强大功能尽可能地发挥出来,这里我就讲一下如何正确使用ABBYY finereader 将PDF 文件转换成可编辑的格式。 工具/原料 ABBYY finereader 11 professional 步骤/方法 首先我们要做的就是打开一个需要转换的 PDF 文件,然后看一下这个文件里面有几种语言,是不是有表格、图片等 然后运行ABBYY finereader 11,点击欢迎界面“文档语言”下拉选择中的更多语言,弹出“语言编辑器”界面,我们设置好PDF 文件中所包含的几种语言。 因为文件文件中有 C++语言的内容,而 ABBYY finereader 中正好也有 C++的选择,那么我们就毫不犹豫的打上勾。设置完毕,点击右下角的“确定”按键。 回到任务界面,我们是想把PDF 转成可编辑的word 文件,所以我们点击中间的“文件(PDF/ 图片)到Microsoft Word”一项 弹出文件选择窗口,选择需要转换的PDF 文件,注意打开窗口的左下角那几个选项,默认都是打勾的,如果不需要的话可以去掉勾,然后点击“打开”按键。 ABBYY finereader 开始加载文件,并且自动 OCR 识别处理。如果页数比较多的话,可能需要花费一些时间,需要耐心等待一下。 由于自动识别会有一些错误,那么我就可以用手动工具进行修正。我们可以选择不同的工具来修正,比如表格被识别成了普通文字,中间没有线框了,那么我们选择“表格”工具,然后把文件中的表格的区域选出来,然后右键“读取区域”就能够手动识别成表格了。还有如果带有文字的图片被自动识别成了文字了,那么我们可以选择图片工具选出页面中的图片区域,然后在你识别本页面其他部分文字的时候,这个区域就会被识别成图片了。 “编辑图像”按键是用来预处理扫描页图片的,因为扫描页有时候会有倾斜、对比度不好、变形等问题,那么先对图像修正一下可以大幅度提高识别的准确率,调整完以后点击右上角的“退出图像编辑器”按键就可以回到上一界面。 识别完毕以后,选择菜单来的“文件”---“将文档另存为”---“Microsoft Word 文档”(如果你需要保存为其他格式你可以自己选择)。 弹出保存对话框,选择保存路径,如果需要保存完就打开文件的话,记得勾选下面的“保存后打开文档”选项,如果电脑配置不高的话不建议勾选此项,因为ABBYY finereader 本身比较耗内存,然后再打开word 的话电脑可能会比较卡。保存完文件,转换过程就基本结束了。 我们打开保存好的word 文件,看看转换的效果怎么样。识别的区域基本上正常,中文英文、图像都可以识别出来,版面略微有些错位,不过还是含有部分错误,我们需要自己修改一下,但是这个已经可以大大降低我们的录入强度了。 注意事项 OCR 识别是肯定会存在错误的,所以大家识别转换完成以后记得要和原文核对。 设置语言种类的话,越少识别率越高,就是说如果文件只有中文的话,那么就设置中文一种语言,不要选择其他语言,这样识别速度也会提高。 ABBYY finereader 理论上可以转换非加密的任意PDF 文件,但是如果扫描件的分辨率或者清晰度比较差的话,那么是不能被正确识别转换的。
用文字识别软件识别扫描图片或PDF的俄文,出来的只是象形的英文。怎么才能识别成俄文?
文字识别软件OCR需要有俄文语言包。下列两款软件可以识别pdf图片中的俄文文字:
1.Readiris pro 版(或corporate版)11以上版本
2.泰比Abbyy finereader 9以上版本。
网上能找到,不过不一定好下。
识别时,要把识别语言改为俄文。
pdf文件能被什么软件文字识别?
FoxitReader 和Adobe Reader 都可以,
个人觉得FoxitReader好用.
关于caj,可以把它转换成word格式。一般用CAJ文件浏览器自带的识别功能,一点一点的复制粘贴,速度较慢、精确度不高。 CAJ文件浏览器下载地址:http://download.enet.com.cn/html/030232002041901.html
推荐快速方法:
从CAJ文件中提取文本前需要做好以下准备工作,安装CAJ文件浏览器5.5,安装Office2003,并完全安装Office工具Microsoft Office Document Imaging,然后在打印机里面会增加Microsoft Office Document Image Writer打印机。 Microsoft Office Document Image可以非常准确的全文件识别转化中文、英文、表格。
CAJ文件的识别:
(一)首先,从网上下载CAJ格式的资料文件保存到本地硬盘上。
(二)然后,启动CAJViewer浏览器程序,并在该程序中打开刚才保存的CAJ格式的文件。浏览文件到最后一页后,不要关闭CAJ浏览器程序。
(三)在CAJ浏览器程序窗口中,选择“文件”→“打印”,并选择打印机为Microsoft Office Document Image Writer打印机,勾选打印到文件选项和确定打印页数。
(四)保存打印文件(*.prn)到适当位置。等待打印完成后,Microsoft Office Document Image 自动打开刚才保存的打印文件。
(五)在Microsoft Office Document Image窗口中,选择“页面”菜单中的“选择所有页面”菜单项,然后选择“工具”菜单中的“使用OCR识别文本”提取文本。
(六)选择“工具”下的 “将文本发送到word”,最后将把整个CAJ文件识别输出到word文件中。
参考资料:http://zhidao.baidu.com/question/4638443.html?si=2
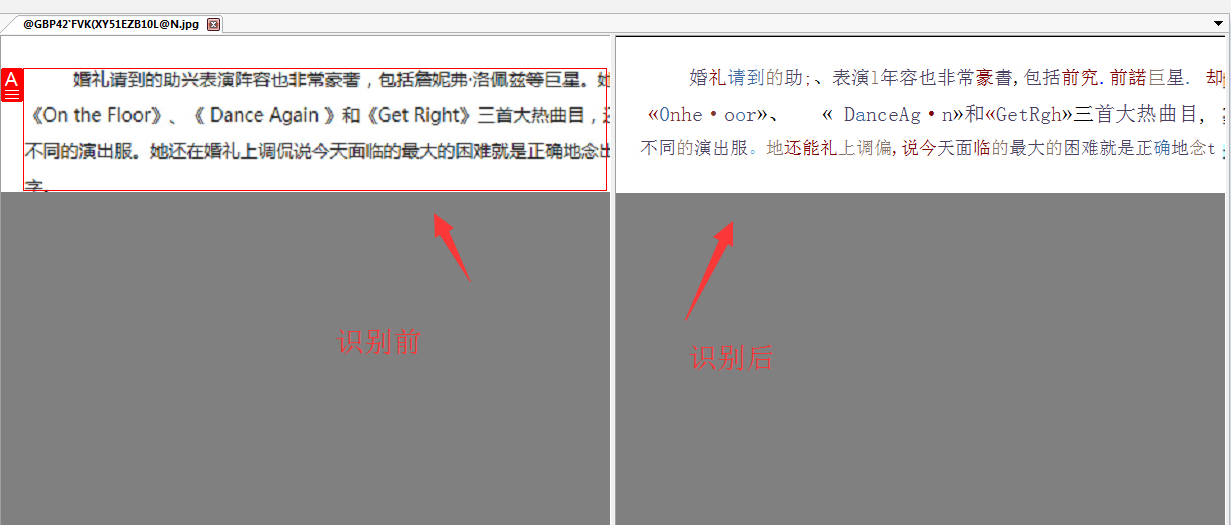
我用AJViewer的文字识别选中PDF上的一段英文,识别出来的是乱码,怎么破???是不是只能识别一种语言?
识别文件出现乱码多半是识别软件的问题,可以换一个识别软件试试看:
一 、首先在电脑中安装好文字识别软件;
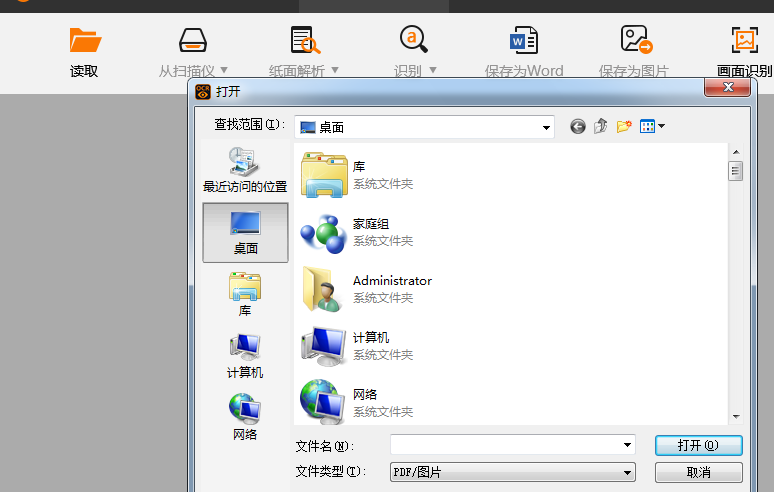
二、然后用它打开要识别的文件;
三、文件打开之后单击开始转换就行了。
有没能识别pdf上英文的软件?
可以用 ABBYY FineReader 11 这款软件将文件转换成word文档,然后编辑或识别!
这是一款将图片或pdf文件中的文字转换成可编辑的软件!
求文字识别软件(主要识别英语单词)
ABBYY FineReader OCR Professional
ABBYY FineReader 7.0专业版是最新、最准确的ABBYY OCR软件版本。它可以为用户提供 最高级别识字精确率,是一个非常节省时间的好方案。FineReader允许你将各种纸张和电子 文件转换、编辑以及重新使用,包括:杂志、报纸、传真、复制和PDF文件。
http://www.google.com/search?q=abbyy&hl=zh-CN&inlang=zh-CN&ie=GB2312
转载请注明出处51数据库 » pdf英文文字识别软件 pdf文字识别软件的具体怎么操作
