
 你太耀眼0
你太耀眼0
NS图是用于取代传统流程图的一种描述方式。 以 SP方法为基础,NS图仅含有下图 的5种基本成分,它们分别表示SP方法的几种标准控制结构。
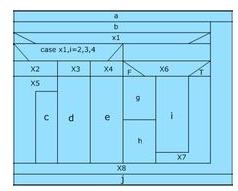
在NS 图中,每个"处理步骤"是用一个盒子表示的,所谓"处理步骤"可以是语句或语句序列。需要时,盒子中还可以嵌套另一个盒子,嵌套深度一般没有限制,只要整张图在一页纸上能容纳得下,由于只能从上边进入盒子然后从下边走出,除此之外没有其他的入口和出口,所以,NS图限制了随意的控制转移,保证了程序的良好结构。用NS图作为详细设计的描述手段时,常需用两个盒子:数据盒和模块盒,前者描述有关的数据,包括全程数据、局部数据和模块界面上的参数等,后者描述执行过程。
NS图的优点:
首先,它强制设计人员按SP方法进行思考并描述他的设计方案,因为除了表示几种标准结构的符号之处,它不再提供其他描述手段,这就有效地保证了设计的质量,从而也保证了程序的质量;第二,NS图形象直观,具有良好的可见度。例如循环的范围、条件语句的范围都是一目了然的,所以容易理解设计意图,为编程、复查、选择测试用例、维护都带来了方便;第三,NS图简单、易学易用,可用于软件教育和其他方面。
NS图的缺点:
手工修改比较麻烦,这是有些人不用它的主要原因。
什么是bs架构
首先你发问的分类错了,呵呵,这个问题应该在.net编程里面。
bs框架正确的叫法应该叫B/S框架,意思是由前端(Browser)和服务器端(Server)组成的系统的框架结构。一般这样的程序是由在客户端处理极少数据,大部分数据都在服务器端处理。举个例子,一些个动态网站就是这样的一个结构。这不是一种编程语言,而是一种抽象的理解形式。说白了就看成是一种模版吧,你可以随便用你喜欢的语言去填写这个模板。
不知道这样你理解不理解,再不明白到我空间留言或者直接向我提问。
全球有几个网络根服务器,都在什么地方?拜托各位了 3Q
根服务器主要用来管理互联网的主目录,全世界只有13台。1个为 根服务器架构 主根服务器,放置在美国。其余12个均为辅根服务器,其中9个放置在美国,欧洲2个,位于英国和瑞典,亚洲1个,位于日本。所有根服务器均由美国政府授权的互联网域名与号码分配机构ICANN统一管理,负责全球互联网域名根服务器、域名体系和IP地址等的管理。 这13台根服务器可以指挥Firefox或InternetExplorer这样的Web浏览器和电子邮件程序控制互联网通信。由于根服务器中有经美国政府批准的260个左右的互联网后缀(如.com、.net等)和一些国家的指定符(如法国的.fr、挪威的.no等),自成立以来,美国政府每年花费近50多亿美元用于根服务器的维护和运行,承担了世界上最繁重的网络任务和最巨大的网络风险。因此可以实事求是地说:没有美国,互联网将是死灰一片。世界对美国互联网的依赖性非常大,当然这也主要是由其技术的先进性和管理的科学性所决定的。所谓依赖性,从国际互联网的工作机理来体现的,就在于“根服务器”的问题。从理论上说,任何形式的标准域名要想被实现解析,按照技术流程,都必须经过全球“层级式”域名解析体系的工作,才能完成。 “层级式”域名解析体系第一层就是根服务器,负责管理世界各国的域名信息,在根服务器下面是顶级域名服务器,即相关国家域名管理机构的数据库,如中国的CNNIC,然后是在下一级的域名数据库和ISP的缓存服务器。一个域名必须首先经过根数据库的解析后,才能转到顶级域名服务器进行解析。 编辑本段只有13台的原因这要从DNS协议(域名解析协议)说起。DNS协议使用了端口上的UDP和TCP协议,UDP通常用于查询和响应,TCP用于主服务器和从服务器之间的传送。由于在所有UDP查询和响应中能保证正常工作的最大长度是512字节,512字节限制了根服务器的数量和名字。 要让所有的根服务器数据能包含在一个512字节的UDP包中,根服务器只能限制在13个,而且每个服务器要使用字母表中的单个字母命名,这也是根服务器是从A~M命名的原因。 编辑本段分布地点下表是这些机器的管理单位、设置地点及最新的IP地址: 字母 IPv4地址 IPv6地址 自治系统编号(AS-number) 旧名称 运作单位 设置地点 #数量(全球性/地区性) 软件 A 198.41.0.4 2001:503:ba3e::2:30 AS19836 ns.internic.net VeriSign 以任播技术分散设置于多处 6/0 BIND B 192.228.79.201 (2004年1月起生效,旧IP地址为128.9.0.107) 2001:478:65::53 (not in root zone yet) none ns1.isi.edu 南加州大学信息科学研究所 (Information Sciences Institute, University of Southern California) 美国加州马里纳戴尔雷伊 (Marina del Rey) 0/1 BIND C 192.33.4.12 AS2149 c.psi.net Cogent Communications 以任播技术分散设置于多处 6/0 BIND D 128.8.10.90 AS27 terp.umd.edu 马里兰大学学院市分校 (University of Maryland, College Park) 美国马里兰州大学公园市 (College Park) 1/0 BIND E 192.203.230.10 AS297 ns.nasa.gov NASA 美国加州山景城 (Mountain View) 1/0 BIND F 192.5.5.241 2001:500:2f::f AS3557 ns.isc.org 互联网系统协会 (Internet Systems Consortium) 以任播技术分散设置于多处 2/47 BIND G 192.112.36.4 AS5927 ns.nic.ddn.mil 美国国防部国防信息系统局 (Defense Information Systems Agency) 以任播技术分散设置于多处 6/0 BIND H 128.63.2.53 2001:500:1::803f:235 AS13 aos.arl.army.mil 美国国防部陆军研究所 (U.S. Army Research Lab) 美国马里兰州阿伯丁(Aberdeen) 1/0 NSD I 192.36.148.17 2001:7fe::53 AS29216 nic.nordu.net 瑞典奥托诺米嘉公司(Autonomica) 以任播技术分散设置于多处 36 BIND J 192.58.128.30 (2002年11月起生效,旧IP地址为198.41.0.10) 2001:503:c27::2:30 AS26415 VeriSign 以任播技术分散设置于多处 63/7 BIND K 193.0.14.129 2001:7fd::1 AS25152 荷兰RIPE NCC 以任播技术分散设置于多处 5/13 NSD L 199.7.83.42 (2007年11月起生效,旧IP地址为198.32.64.12) 2001:500:3::42 AS20144 ICANN 以任播技术分散设置于多处 37/1 NSD M 202.12.27.33 2001:dc3::35 AS7500 日本WIDE Project 以任播技术分散设置于多处 5/1 BIND
ons模拟器是什么东西
Ons模拟器是onscripter的缩写,ons模拟器是一款可以用来玩pc上移植的galgame的软件,最早的ons模拟器出现在Linux平台上,但后来因为某些原因而停止对ons的开发,再后来,wm平台上也出现了ons,但好景不长,该平台的模拟器也停止了开发。现如今,仍在开发的ons就是安卓和塞班了,其中以安卓的开发最为强劲,其超高的兼容性令开发者移植游戏要相对简单得多。
amd与intel结构图
AMD的CPU由于工作原理不同,所以不能全看频率 为了跟INTEL比较,所谓3000+就是相当于3GHZ的意思!~实际上达不到,大致可以相当于2.8G的样子!~
AMD与Intel的区别
CPU的处理性能不应该去看主频,而INTEL正是基于相当相当一部分人对CPU的不了解,采用了加长管线的做法 来提高频率,从而误导了相当一部分的人盲目购买。CPU 的处理能力简单地说可以看成:实际处理能力=主频*执行效率,就拿P4E来说他的主频快是建立在使用了更长的管线基础之上的,而主频只与每级管线的执行速度有关,与执行效率无关,加长管线的好处在与每级管线的执行 速度较快,但是管线越长(级数越多)执行效率越低 下,AMD的PR值可能会搞得大家一头雾水,但是却客观划 分了与其对手想对应的处理器的能力。为什么实际频率 只有1.8G的AMD 2500+处理器运行速度比实际频率2.4G的 P4-2.4B还快?为什么采用0.13微米制程的Tulatin核心 的处理器最高只能做到1.4G,反而采用0.18微米制程的
Willamette核心的处理器却能轻松做到2G?下面我们就来分析一下到底是什么原因导致以上两种“怪圈”的存在。
每块CPU中都有“执行管道流水线”的存在(以下简称“管线”),管线对于CPU的关系就类似汽车组装线与汽车之间的关系。CPU的管线并不是物理意义上供数据输入输出的的管路或通道,它是为了执行指令而归纳出的“下一步需要做的事情”。每一个指令的执行都必须经过相同的步骤,我们把这样的步骤称作“级”。管线中的“级”的任务包括分支下一步要执行的指令、分支数据的运算结果、分支结果的存储位置、执行运算等等…… 最基础的CPU管线可以被分为5级: 1、取指令2、译解指令 3、演算出操作数 4、执行指令 5、存储到高速缓存 你可能会发现以上所说的5级的每一级的描述都非常的概括,同时如果增加一些特殊的级的话,管线将会有所延长: 1、取指令1 2、取指令2 3、译解指令1 4、译解指令2 5、演算出操作数 6、分派操作 7、确定时 8、执行指令 9、存储到高速缓存1 10、存储到高速缓存2 无论是最基本的管线还是延长后的管线都是必须完成同样的任务:接受指令,输出运算结果。两者之间的不同是:前者只有5级,其每一级要比后者10级中的每一级处理更多的工作。如果除此以外的其它细节都完全相同的话,那么你一定希望采用第一种情况的“5级”管线,原因很简单:数据填充5级要比填充10级容易的多。而且如果处理器的管线不是始终充满数据的话,那么将会损失宝贵的执行效率——这将意味着CPU的执行效率会在某种程度上大打折扣。
那么CPU管线的长短有什么不同呢?——其关键在于
管线长度并不是简单的重复,可以说它把原来的每一级
的工作细化,从而让每一级的工作更加简单,因此在
“10级”模式下完成每一级工作的时间要明显的快于“5
级”模式。最慢的(也是最复杂)的“级”结构决定了
整个管线中的每个“级”的速度——请牢牢记住这一
点! 我们假设上述第一种管线模式每一级需要1个时钟
周期来执行,最慢可以在1ns内完成的话,那么基于这种
管线结构的处理器的主频可以达到1GHz(1/1ns =
1GHz)。现在的情况是CPU内的管线级数越来越多,为此
必须明显的缩短时钟周期来提供等于或者高于较短管线
处理器的性能。好在,较长管线中每个时钟周期内所做
的工作减少了,因此即使处理器频率提升了,但每个时
钟周期缩短了,每个“级”所用的时间也就相应的减少
了,从而可以让CPU运行在更高的频率上了。
如果采用上述的第二种管线模式,可以把处理器主频
提升到2GHz,那么我们应该可以得到相当于原来的处理
器2倍的性能——如果管线一直保持满载的话。但事实并
非如此,任何CPU内部的管线在预读取的时候总会有出错
的情况存在,一旦出错了就必须把这条指令从第一级管
线开始重新执行,稍微计算一下就可以得出结论:如果
一块拥有5级管线的CPU在执行一条指令的时候,当执行
到第4级时出错,那么从第一级管线开始重新执行这条指
令的速度,要比一块拥有10级管线的CPU在第8级管线出
错时重新执行要快的多,也就是说我们根本无法充分的
利用CPU的全部资源,那么我们为什么还需要更高主频的
CPU呢??
回溯到几年以前,让我们看看当时1.4GHz和1.5GHz
的奔腾四处理器刚刚问世之初的情况:当时Intel公司将
原奔腾三处理器的10级管线增加到了奔腾四的20级,管
线长度一下提升了100%。最初上市的1.5GHz奔腾四处理
器曾经举步维艰,超长的管线带来的负面影响是由于预
读取指令的出错从而造成的执行效率严重低下,甚至根
本无法同1GHz主频的奔腾三处理器相对垒,但明显的优
势就是大幅度的提升了主频,因为20级管线同10级管线
相比,每级管线的执行时间缩短了,虽然执行效率降低
了,但处理器的主频是根据每级管线的执行时间而定
的,跟执行效率没有关系,这也就是为什么采用0.18微
米制程的Willamette核心的奔腾四处理器能把主频轻松
做到2G的奥秘! 固然,更精湛的制造工艺也能对提升处
理器的主频起到作用,当奔腾四换用0.13微米制造工艺
的Northwood 核心后,主频的优势才大幅度体现出来,
一直冲到了3.4G,长管线的CPU只有在高主频的情况下才
能充分发挥优势——用很高的频率、很短的时钟周期来
弥补它在预读取指令出错时重新执行指令所浪费的时
间。 但是,拥有20级管线、采用0.13微米制程的
Northwood核心的奔腾四处理器的理论频率极限是3.5G,
那怎么办呢?Intel总是会采用“加长管线”这种屡试不
爽的主频提升办法——新出来的采用Prescott核心的奔
腾四处理器(俗称P4-E),居然采用了31级管线,通过
上述介绍,很明显我们能得出Prescott核心的奔四处理
器在一个时钟周期的处理效率上会比采用Northwood核心
的奔四处理器慢上一大截,也就是说起初的P4-E并不比
P4-C的快,虽然P4-E拥有了更大的二级缓存,但在同频
率下,P4-E绝对不是P4-C的对手,只有当P4-E的主频提
升到了5G以上,才有可能跟P4-3.4C的CPU对垒,著名的
CPU效能测试软件SuperPi就能反应出这一差距来:P4-
3.4E的处理器,运算Pi值小数点后100万位需要47秒,这
仅相当于P4-2.4C的成绩,而P4-3.4C运算只需要31秒,
把同频率下的P4-3.4E远远的甩在了后面!! AMD 2500+
处理器,采用了10级管线,只有1.8G的主频却能匹敌
2.4G的P4;苹果电脑的G4处理器,更是采用了7级管线,
只有1.2G的主频却能匹敌2.8C的P4,这些都要归功于更
短的管线所带来的更高的执行效率,跟它们相比,执行
效率方面Intel输在了管线长度上,但主频提升方面
Intel又赢在了管线长度上,因为相对于“管线”这个较
专业的问题,大多数消费者还是陌生的,人们只知道
“处理器的主频越高速度就越快”这个片面的、错误
的、荒谬的理论!!这就是Intel的精明之处
显卡的结构及工作原理?
显卡的结构和工作原理
显卡是目前大家最为关注的电脑配件之一了,他的性能好坏直接关系到显示性能的好坏及图像表现力的优劣等等。然而许多初学者对显卡这个东西并不是十分了解的,下面笔者搜集了一批资料并以图解的形式对显卡结构做一简单的介绍,希望你看后能对显卡有一定的了解。
显卡的基本结构
显卡的主要部件包括:显示芯片,显示内存,RAMDAC等。
显示芯片:一般来说显卡上最大的芯片就是显示芯片,显示芯片的质量高低直接决定了显示卡的优劣,作为处理数据的核心部件,显示芯片可以说是显示卡上的CPU,一般的显示卡大多采用单芯片设计,而专业显卡则往往采用多个显示芯片。由于3D浪潮席卷全球,很多厂家已经开始在非专业显卡上采用多芯片的制造技术,以求全面提高显卡速度和档次。
显示内存:与系统主内存一样,显示内存同样也是用来进行数据存放的,不过储存的只是图像数据而已,我们都知道主内存容量越大,存储数据速度就越快,整机性能就越高。同样道理,显存的大小也直接决定了显卡的整体性能,显存容量越大,分辨率就越高。
一:结构--全面了解显示卡(一)
一.图解显示卡。
1.线路板。
显卡的线路板是显卡的母体,显卡上的所有元器件必须以此为生。目前显卡的线路板一般采用的是6层PCB线路板或4层PCB线路板,如果再薄,那么这款显卡的性能及稳定性将大打折扣。另外,大家可看见显卡的下面有一组“金手指”(显示卡接口),它有ISA/PCI/AGP等规范,它是用来将显卡插入主板上的显卡插槽内的。当然,为了让显卡和主机更好的固定,显卡上需要有一块固定片;为了让显卡和显示器及电视等输入输出设备相连,各种信号输出输入接口也是必不可少的。
2.显卡上常见的元器件。
现在的显卡随着技术上的进步,其采用的元器件是越来越少越来越小巧。下面我们给大家介绍几种显卡上常见的元器件。
a.主芯片:主芯片是显示卡的灵魂。可以说采用何种主显示芯片便决定了这款显示卡性能上的高低。目前常见的显卡主芯片主要有nVidia系列及ATI系列等等,如Geforce2 GTS,Geforce2 MX,Geforce3,ATI Radeon等。此外,由于现在的显卡频率越来越高工作时发热量也越来越大,许多厂家在显卡出厂家已给其加上了一个散热风扇。
b.显存:显存也是必不可少的。现在的显卡一般采用的是SDRAM,SGRAM,DDR三种类别的显存,以前常见的EDO等类别的显存已趋淘汰。它们的差别是--SGRAM显存芯片四面皆有焊脚,SDRAM显存只有两边有焊脚,而DDR显存除了芯片表面标记和前两者不同外,那就是芯片厚度要比前两者明显薄。
c.电容电阻:电容电阻是组成显卡不能或缺的东西。显卡采用的常见的电容类型有电解电容,钽电容等等,前者发热量较大,特别是一些伪劣电解电容更是如此,它们对显卡性能影响较大,故许多名牌显卡纷纷抛弃直立的电解电容,而采用小巧的钽电容来获得性能上的提升。电阻也是如此,以前常见的金属膜电阻碳膜电阻越来越多的让位于贴片电阻。
d.供电电路:供电电路是将来自主板的电流调整后供显卡更稳定的工作。由于显示芯片越造越精密,也给显卡的供电电路提出了更高的要求,在供电电路中各种优良的稳压电路元器件采用是少不了的。
e.FLASH ROM:存放显卡BIOS文件的地方。
f.其它:除此之外,显卡上还有向显卡内部提供数/模转换时钟频率的晶振等小元器件。
全面了解显示卡
PCB板
PCB板是一块显卡的基础,所有的元件都要集成在PCB板上,所以PCB板也影响着显卡的质量。目前显卡主要采用黄色和绿色PCB板,而蓝色、黑色、红色等也有出现,虽然颜色并不影响性能,但它们在一定程度上会影响到显卡出厂检验时的误差率。另外,目前不少显卡采用4层板设计,而一些做工精良的大厂产品多采用了6层PCB板,抗干扰性能要好很多。PCB板的好坏直接影响显示的稳定性。
显示芯片
我们在显示卡上见到的“个头”最大的芯片就是显示芯片,它们往往被散热片和风扇遮住本来面目,显示芯片专门负责图像处理。常见的家用型显卡一般都带有一枚显示芯片,但也有多芯片并行处理的显卡,比如ATI RAGE MAXX和大名鼎鼎的3dfx Voodoo5系列显卡。
显示芯片按照功能来说主要分为“2D”(如S3 64v+)“3D”(如3dfx Voodoo)和"2D+3D"(如Geforce MX)几种,目前流行的主要是2D+3D的显示芯片。
位(bit指的是显示芯片支持的显存数据宽度,较大的带宽可以使芯片在一个周期内传送更多的信息,从而提高显卡的性能。现在流行的显示芯片多位128位和256位,也有一小部分64位芯片显卡。“位”是显示芯片性能的一项重要指标,但我们并不能按照数字倍数简单判定速度差异。
显示内存
显存也是显卡的重要组成部分,而且显存质量、速度、带宽等的重要性已经越来越明显。显存是用来存储等待处理的图形数据信息的,分辨率越高,屏幕上显示的像素点也越多,相应所需显存容量也较大。而对于目前的3D加速卡来说,则需要更多的显存来存储Z-Buffer数据或材质数据等。
我们知道,在显卡工作中,显示芯片将所处理的图形数据信息传送到显存中,随后RAMDAC从显存中读取数据并将数字信号转化为模拟信号,输出到显示器上。所以,显存的速度及数据传输带宽直接影响了显卡的速度。数据传输带宽是指显存一个周期内可以读入的数据量影响显卡的速度。显存容量决定了显卡支持的分辨率、色深,而刷新率由RAMDAC决定。
显存可以分为两大类:单端口显存和双端口显存。前者从显示芯片读取数据及向RAMDAC传输数据经过同一端口,数据的读写和传输无法同时进行;顾名思义,双端口显存则可以同时进行数据的读写与传输。目前主要流行的显存有SDRAM、SGRAM、DDR RAM、VRAM、WRAM等。
RAMDAC(数/模转换器)
RAMDAC作用是将显存中的数字信号转换成显示器能够识别的模拟信号,速度用“MHz”表示,速度越快,图像越稳定,它决定了显卡能够支持的最高刷新频率。我们通常在显卡上见不到RAMDAC模块,那是因为厂商将RAMDAC整合到显示芯片中以降低成本,不过仍有部分高档显卡采用了独立的RAMDAC芯片。
VGA BIOS
VGA BIOS存在于Flash ROM中,包含了显示芯片和驱动程序间的控制程序、产品标识等信息。我们常见的Flsah ROM编号有29、39(见图1)和49开头的3种,这几种芯片都可以通过专用程序进行升级,改善显卡性能,甚至可以给显卡带来改头换面的效果。
图1 VGA BIOS
VGA功能插针
VGA功能插针(见图2)是显卡与外部视频设备交换数据的通道,通常用于扩展显卡的视频功能,比如连接解压卡等,虽然它存在于很多显卡当中,但利用率非常低。
图2 VGA插针
VGA 插座(D-SUB)
VGA插座一般为15针RGB接口(见图3),某些书籍及报刊称之为D-SUB接口。显卡与显示器之间的连接需要VGA插座来完成,它负责向显示器输出图像信号。在一般显卡上都带有一个VGA插座,但也有部分显卡同时带有两个VGA插座,使一块显示卡可以同时连接两台显示器,比如MGA G400DH和双头GeForce MX。
图3 VGA插座
另外,部分显卡还同时带有视频输入(Video in)、输出(Video out)端子(见图4)、S端子(见图5)或数字DVI接口(见图6)。视频输出端口和S端子的出现使得显卡可以将图像信号传输到大屏幕彩电中,获取更佳的视觉效果。数字DVI接口用于连接LCD,这需要显示芯片的支持。具有这些接口的显卡通常也可以称为双头显卡,双头显卡一般需要单独的视频控制芯片。现在市场上有售的耕升的GeForce2 ULT显卡同时拥有DVI接口和S-Video接口,是少见的全能产品。
工作原理
我们必须了解,资料 (data) 一旦离开 CPU,必须通过 4 个 步骤,最后才会到达显示屏:
1、从总线 (bus) 进入显卡芯片 -将 CPU 送来的资料送到显卡芯片里面进行处理。 (数位资料)
2、从 video chipset 进入 video RAM-将芯片处理完的资料送到显存。 (数位资料)
3、从显存进入 Digital Analog Converter (= RAM DAC),由显示显存读取出资料再送到 RAM DAC 进 行资料转换的工作(数位转类比)。 (数位资料)
4、从 DAC 进入显示器 (Monitor)-将转换完的类比资料送到显示屏 (类比资料)
如同你所看到的,除了最后一步,每一步都是关键,并且对整体的显示效能 (graphic performance) 关系十分重大。
注: 显示效能是系统效能的一部份,其效能的高低由以上四步所决定,它与显示卡的效能 (video performance) 不太一样,如要严格区分,显示卡的效能应该受中间两步所决定,因为这两步的资料传输都是在显示卡的内部。第一步是由 CPU 进入到显示卡里面,最后一步是由显示卡直接送资料到显示屏上,这点要了解。
最慢的步骤就是整体速度的决定步骤 (注: 例如四人一组参加 400 公尺接力,其中有一人跑的特别慢,全组的成绩会因它个人而被拖垮,也许会殿后。但是如果他埋头苦练,或许全队可以得第一,所以跑的最慢的人是影响全队成绩的关键,而不是哪些已经跑的很快的人)。
现在让我们来看看每一步所代表的意义及实际所发生的事情:
CPU 和显卡芯片之间的资料传输
这受总线的种类和总线的速度(也就是外频),主机板和他的芯片组所决定。 目前最快的总线是 PCI bus,而 VL bus, ISA, EISA and NuBus (Macs 专用) 效能就比较低。
现在流行的AGP并不是一种总线,而只是一种接口方式(注: PCI bus 是 32 bit data path,也就是说 CPU 跟 显示卡之间是以一次 4 byte 的资料在对传,其他的 bus 应该是 16 bit data path)。
PCI bus 的最快速度是 33 MHz 。
显卡芯片和显存之间的资料传输以及从显存到 RAM DAC 的资料传输
我把这两步放在一起是因为这里是影响显示卡效能的关键所在, 假如你不考虑显卡芯片的个别差异。
显示卡的最大的问题就是,可怜的显存夹在这两个非常忙碌的装置之间 (显卡芯片和 RAMDAC),必须随时受它们两个差遣。
每一次当显示屏画面改变,芯片就必须更改显示显存里面的资料 (这动作是连续进行的,例如移动滑鼠游标,键盘游标......等等)。 同样的,RAM DAC 也必须不断地读取显存上的资料,以维持画 面的刷新。 你可以看到,显存在他们之间被捉的牢牢的。
所以后来出现了一些聪明的做法,像是使用 VRAM, WRAM, MDRAM, SGRAM, EDO RAM, 或增加 video bus 的大小如 32 bit, 64bit, 还有现在刚出现的 128 bit。
解析度越高,从芯片传到显存的资料就越多。 而 RAM DAC 从显存读取资料的速度就要更快才行。 你可以看到,芯片和和RAM DAC 随时都在对显存 进行存取的工作。
一般 DRAM 的速度只能被存取到一个最大值(如 70ns 或 60ns),所以 在芯片结束了存取 (read/write) 显存之后, 才能换 RAM DAC 去读取显存,如此一直反覆不断。
显卡的主要术语与参数
一.明白显卡的常见术语。
了解了显卡的外表,最后让我们再来了解一下显卡的流行术语,这样对你认识显卡更有由表及里的帮助作用。
1.AGP:(ACCELERATED GRAPHICS PORT图形加速端口)AGP实际上是PCI接口的超集,它做为一种新型接口将显示卡同主板芯片组进行了直接连接,从而大幅度提高了电脑对3D图形的处理能力。在处理大的纹理图形时AGP显卡除了使用卡上的显存外还可以通过DIME直接内存执行功能使用系统内存,AGP显卡视频传输率在X2模式下就可达到533MB/S。
*AGP8X:AGP8X是Intel制定的新一代的图像传输规格,它将作为下一代的个人电脑及工作站的新显示标准。AGP (Accelerated Graphics Port)是由Intel公司所制订的显示接口标准,速度已由最初的AGP 1x (264 MBytes/sec,3.3v)到现在的AGP 4x (1 GBytes/sec,1.5v),因为AGP拥有高速频宽,所以广受众多显示芯片厂家的支持,推出了很多支持AGP 4X/PRO的不同产品来以满足用户对图像运算、高画质要求的要求。Intel宣布的AGP 8x,依旧使用32-bit的总线架构,而速度方面则提升至533 MHz,及支持2GBytes/sec,是AGP 4x的两倍。速度的提升,即代表了显示芯片制造商能更好的利用AGP 8x的优点来充份发挥显示芯片的效能。
2.API。
API全称为(Application Programming Interface)应用程序接口。
API的原理是当某一个应用程序提出一个制图请求时,这个请求首先要被送到操作系统中,然后通过GDI(图形设备接口)和DCI(显示控制接口)对所要使用的函数进行选择。而现在这些工作基本由Direct X来进行,它远远超过DCI的控制功能,而且还加入了3D图形API(应用程序接口)和Direct3D。显卡驱动程序判断有那些函数是可以被显卡芯片集运算,可以进行的将被送到显卡进行加速。如果某些函数无法被芯片进行运算,这些工作就交给CPU进行(影响系统速度)。运算后的数字信号写入帧缓存中,最后送入RAMDAC,在转换为模拟信号后输出到显示器。由于API是存在于3D程序和3D显示卡之间的接口,它使软件运行在硬件之上,为了使用3D加速功能,就必须使用显示卡支持的API来编写程序,比如Glide, Direct3D或OpenGL等等来获得性能上的提升。
常见的API主要有以下几种:
*.Direct X。
说起显卡我们不得不说说它。这是微软公司专为PC游戏开发的API(应用程序接口),它的主要特点是:比较容易控制,可令显卡发挥不同的功能,并与WINDOWS系统有良好的兼容性。
*.OpenGL。
OpenGL开放式图形界面是由SG公司开发用于WINDOWS,MACOS,UNIX等系统上的API。它除了提供有许多图行运算处理功能外,其3D图形功能很强,甚至超过Direct X很多。
*.Glide。
这是3DFX公司首先在VOODOO系列显卡上应用的专用3D API,它可以最大限度的发挥VOODOO显示芯片的3D图形处理能力。由于它很少考虑兼容性,所以工作效率要比OpenGL和D3D要高。
3.RAMDAC。
RAMDAC(RANDOM ACCESS MEMORY DAC,数模转换芯片)它的作用是将电脑内的数字信号代码转换为显示器所用的模拟信号的东西。此芯片决定显示器所表现出的分辨率及图像显示速度。RAM DAC根据其寄存器的位数分为8位,16位,24位等等,8位RAMRAC只能显示256色,而真彩卡支持的16M色,它的RAMRAC必须为24位。另外,RAM DAC的工作速度越高,则相应的显示速度也越快,如在75Hz的刷新率和1280X1024的分辨率下RAM DAC的速度至少要达到150MHz。
4.显存。
显存,显示存储器,其作用是以数字形式存储图行图像资料。通过专门的图形处理芯片可直接从卡上的显存调用有关图形图像资料,从而减轻了CPU的负担缩短了通过总线传输的时间,提高了显示速度,可以说显存的大小与速度直接影响到视频系统的图形分辨率,色彩精度和显示速度。常见的显存和当时主流的内存使用情况基本相同
显示卡(Display Card),也叫显卡,是电脑最基本组成部分之一。显卡控制着PC的脸面——显示器,使它能够呈现供我们观看的字符和图形画面。早期的显卡只是单纯意义的显卡,只起到信号转换的作用;目前我们一般使用的显卡都带有图形加速功能,所以也叫做“图形加速卡”。本期我们将为大家介绍有关显示卡的知识。
显示卡通常由总线接口、PCB板、显示芯片、显存、RAMDAC、VGA BIOS、VGA功能插针、VGA插座及其他外围元件构成
主要参数
CGA (COlor Gaphics Adapter:彩色图形适配卡〕
IBM公司于1982年开发并推出了一种可支持彩色显示器的显示即CGA卡,它能够显示16种颜色,可达到640X200的分辨率,可工作于文本和图形方式下。
EGA (Enhanced Graphics Adapter:增强图形适配卡)
在CGA的基础上IBM公司于1984年推出了EGA卡。EGA将显示分辨率提高到640X350,同时与CGA完全兼容,可显示的颜色数据提高到了64种显示内存也扩展到256K。
VGA (Video Graphics Array:视频图形阵列)
1987年IBM公司在PS/2 (微通道计算机)电脑上,首次推了VGA卡,今天虽已难觅PS/2的影踪,但VGA早已成为业界标准。VGA达到了640X480的分辨率,并与MDA、CGA、EGA保持兼容,它增加二个6位DAC转换电路从而首次实现了从显示卡上直接输出R.G.B模拟信号到显示器,可显示的颜色增加到256色并且可支持大于256K的显示存储器容量。
SVGA (Suoer VGA 超级视频图形阵列)
SVGA是由VESA(视频电了标准学会,一个由众多显示卡生产而所组成的联盟)1989年推出的。它规定,超过VGA 640X480分辨率的所有图形模式均称为SVGA,SVGA标准允许分辨率最高达到1600X1200,颜色数最高可达到16兆(1600万)色。同时它还规定在800X600的分辨率下,至少要达到72Hz的刷新频率。
IBM在VGA的基础上,1989年推出了8514A,它可以达到1024X768的分辨率是对VGA的低分辨率的提高,但由于这一标准只能用于IBM的PS/2电脑其技术资料不对外公开,并且采用了导致高闪烁的隔行扫描方式,因此,未能像IBM过去的几个产品那样成为业界标,很快就被淘汰了。
XGA (Extended Graphic Array:增强图形阵列)
由于8514A的失败,IBM在1990年又推出了XGA,XGA与8514A同样达到了1024X768的分辨率,在64OX480时可以达到65536种颜色。它最大的改进是允许逐行扫描方式并且针对Windows的图形界面操作作了很大的改进,用硬件方式实现了图形加速,如位块传输、画线、硬件子图形等,它还使用了VRAM作为显示存储器,因此大大提高了显示速度。
显示分辨率 (Resolution)
指视频图像所能达到的清晰度,由每幅图像在显示屏幕的水平和垂直方向上的像素点数来表示比如说某显示分辨率为640X480。就是说凡水平方向上有640个像素、垂直方向上有480个像素。
像素(Pixel)
Pixel是Picture element (图像元素)的简写。像素是组成显示屏幕上的点,是显示画面的最小组成单位。
点距(Dot Pitch)
指显示屏幕上同色荧光点的最短距离,它决定着像素的大小和显示图像的清晰度。通点距有0.39,0.31,0.28,0.26,0.25及0.20等几种规格。
颜色深度(Color Depth)
指每个像素可显示的颜色数。每个像素可显示的颜色数取决于显示卡上给它所分配的DAC位数,位数越高,每个像素可显示出的颜色数目就越多。但是在显示分辨率一定的情况下一块显示卡所能显示的颜色数目还取决于其显示存储器的大小。比如一块两兆显存的显示卡,在1024X768的分辨率下,就只能显示16位色(即65536”种颜色),如果要显示24位彩色(16.8M), 就必须要四兆显存。
伪彩色(Pseudo Color)
如果每个像素使用的是1个字节的DAC位数 (即8位),那么每个像素就可以显示出256种颜色,这种颜色模式称为“伪彩色”又叫8位色。
高彩色(High Color)
如果给每个像素分配2个字节的DAC位数(即16位),则每个像素可显示的颜色最多可以达到65536种,这种颜色模式称为“高彩色” ,又叫“16位色”。
真彩色(True Color)
在显示存储器容量足够的情况下,如果给每个像素分配3个字节的DAC (即24位),那么每个像素可显示的颜色则可达到不可思议的1680万种(168M色)——尽管人眼可分辨的颜色只是其中很少一部分而已,这种颜色模式就是“真彩色”,又叫“24位色”。目前较好的显示卡已经达到了32位色的水平。
刷新频率(Refresh Rate )
在显示卡输出的同步信号控制下,显示器电于束先对屏幕从左到右进行水平扫描,然后又很快地从下到上进行垂亘扫描,这两遍扫描完成后才组成一幅完整的画面,这个扫描的速度就是刷新频率,意思就是每秒钟内屏幕画向更新的次数,刷新频率越高,显示画面的闪烁就越小。
带宽(Bandwidth )
显示存储器同时输入输出数据的最大能力,常以每秒存取数据的最大字节数MB/S)来表示越高的刷新频率往往需要越大的带宽。
纹理映射
每一个3D造型都是由众多的三角形单元组成的,要使它显示的更加真实的话,就要在它的表面粘贴上模拟的纹理和色彩,比如一块大理石的纹理等。而这些纹理图像是事先放在显示存储器中的,将之从存储器中取出来并粘贴到3D造型的表面,这就是纹理映射。
Z缓冲(Z-BUFFERING)
Z的意思就是除X 、Y轴以外的第三轴,即3D立体图型的深度。Z缓冲是指在显示存储器中预先存放不同的3D造型数据,这样,当画面中的视角发生变化时,可以即时地将这些变化反映出来从而避免了由于运算速度滞后所造成的图形失真。
3D显卡
3D显卡术语简介
如今3D显示技术的发展日新月异,各种最新一代的显示卡蕴含着最新的技术不断的涌现,各个显示芯片厂商也都在新产品的介绍中展示着产品的独特性能与3D特效,其中许多诸如“三线过滤”、“阿尔法混合”、“材质压缩”、“硬件T&L”等等名词可能会令您疑惑不解,本文就是为您通俗的来解释阐述这些专业术语,以使您能对枯燥的3D术语能有所把握。
这些最新的3D显示技术与特性是在目前3D显卡中正流行的或是将要广泛流行的技术标准,展望未来,在21世纪中显示技术也必将进入一个新的阶段,面对着纷繁的显示技术与显卡市场,要知最后花落何家呢,还是让我们拭目以待吧!
16-, 24-和32-位色
16位色能在显示器中显示出65,536种不同的颜色,24位色能显示出1670万种颜色,而对于32位色所不同的是,它只是技术上的一种概念,它真正的显示色彩数也只是同24位色一样,只有1670万种颜色。对于处理器来说,处理32位色的图形图像要比处理24位色的负载更高,工作量更大,而且用户也需要更大的内来存运行在32位色模式下。
2D卡
没有3D加速引擎的普通显示卡。
3D卡
有3D图形芯片的显示卡。它的硬件功能能够完成三维图像的处理工作,为CPU减轻了工作负担。通常一款3D加速卡也包含2D加速功能,但是还有个别的显示卡只具有3D图像加速能力,比如Voodoo2。
Accelerated Graphics Port (AGP)高速图形加速接口
AGP是一种PC总线体系,它的出现是为了弥补PCI的一些不足。AGP比PCI有更高的工作频率,这就意味着它有更高的传输速度。AGP可以用系统的内存来当作材质缓存,而在PCI的3D显卡中,材质只能被储存在显示卡的显存中。
Alpha Blending(透明混合处理)
它是用来使物体产生透明感的技术,比如透过水、玻璃等物理看到的模糊透明的景象。以前的软件透明处理是给所有透明物体赋予一样的透明参数,这显然很不真实;如今的硬件透明混合处理又给像素在红绿蓝以外又增加了一个数值来专门储存物体的透明度。高级的3D芯片应该至少支持256级的透明度,所有的物体(无论是水还是金属)都由透明度的数值,只有高低之分。
Anisotropic Filtering (各向异性过滤)
(请先参看二线性过滤和三线性过滤)各向异性过滤是最新型的过滤方法,它需要对映射点周围方形8个或更多的像素进行取样,获得平均值后映射到像素点上。对于许多3D加速卡来说,采用8个以上像素取样的各向异性过滤几乎是不可能的,因为它比三线性过滤需要更多的像素填充率。但是对于3D游戏来说,各向异性过滤则是很重要的一个功能,因为它可以使画面更加逼真,自然处理起来也比
三线性过滤会更慢。
Anti-aliasing(边缘柔化或抗锯齿)
由于3D图像中的物体边缘总会或多或少的呈现三角形的锯齿,而抗锯齿就是使画面平滑自然,提高画质以使之柔和的一种方法。如今最新的全屏抗锯齿(Full Scene Anti-Aliasing)可以有效的消除多边形结合处(特别是较小的多边形间组合中)的错位现象,降低了图像的失真度,全景抗锯齿在进行处理时, 须对图像附近的像素进行2-4次采样, 以达到不同级别的抗锯齿效果。3dfx在驱动中会加入对2x2或4x4抗锯齿效果的选择, 根据串联芯片的不同, 双芯片Voodoo5将能提供2x2的抗锯齿效果, 而四芯片的卡则能提供更高的4x4抗锯齿级别。 简而言之,就是将图像边缘及其两侧的像素颜色进行混合,然后用新生成的具有混合特性的点来替换原来位置上的点以达到柔化物体外形、消除锯齿的效果。
API(Application Programming Interface)应用程序接口
API是存在于3D程序和3D显示卡之间的接口,它使软件运行与硬件之上。为了使用3D加速功能,就必须使用显示卡支持的API来编写程序,比如Glide, Direct3D或是OpenGL。
Bi-linear Filtering(二线性过滤)
是一个最基本的3D技术,现在几乎所有的3D加速卡和游戏都支持这种过滤效果。当一个纹理由小变大时就会不可避免的出现“马赛克”现象,而过滤能有效的解决这一问题,它是通过在原材质中对不同像素间利用差值算法的柔化处理来平滑图像的。其工作是以目标纹理的像素点为中心,对该点附近的4个像素颜色值求平均,然后再将这个平均颜色值贴至目标图像素的位置上。通过使用双线性过滤,虽然不同像素间的过渡更加圆滑,但经过双线性处理后的图像会显得有些模糊。
CPU的核心数与主频哪个更决定速度
不是一个概念!
相对来说主频高,运算速度快一些,相当于个人能力
核心数解决的是多线程的问题,也就是说同时干活的人的多少的问题
而且快与慢得看程序对多线程多核心的支持情况,有没有做相关的优化!
以前就出现过双核玩游戏还不如单核快的例子!
主要看你做干什么了!
转载请注明出处51数据库 » 软件架构ns ns结构流程图是什么
