
 踏过荆棘
踏过荆棘
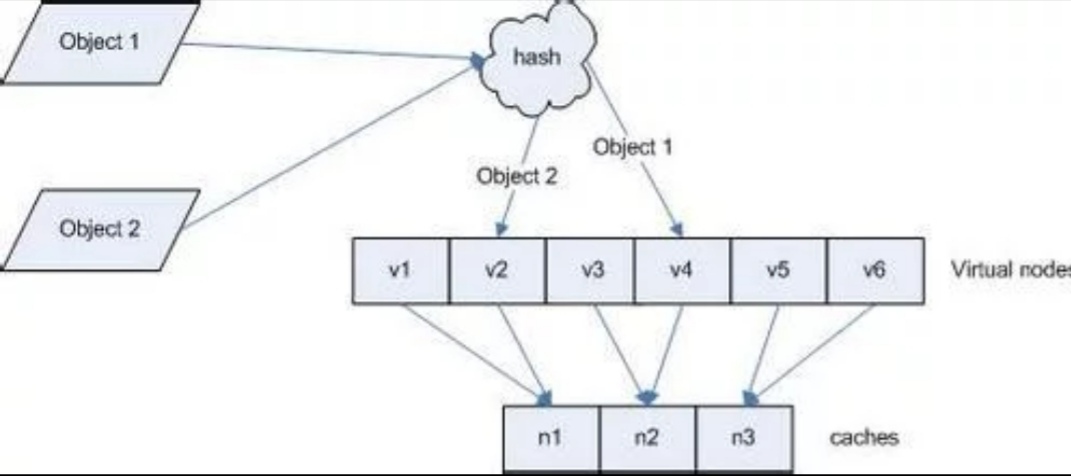
散列表,它是基于高速存取的角度设计的,也是一种典型的“空间换时间”的做法。顾名思义,该数据结构能够理解为一个线性表,可是当中的元素不是紧密排列的,而是可能存在空隙。
散列表(Hash table,也叫哈希表),是依据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
比方我们存储70个元素,但我们可能为这70个元素申请了100个元素的空间。70/100=0.7,这个数字称为负载因子。
我们之所以这样做,也是为了“高速存取”的目的。我们基于一种结果尽可能随机平均分布的固定函数H为每一个元素安排存储位置,这样就能够避免遍历性质的线性搜索,以达到高速存取。可是因为此随机性,也必定导致一个问题就是冲突。
所谓冲突,即两个元素通过散列函数H得到的地址同样,那么这两个元素称为“同义词”。这类似于70个人去一个有100个椅子的饭店吃饭。散列函数的计算结果是一个存储单位地址,每一个存储单位称为“桶”。设一个散列表有m个桶,则散列函数的值域应为[0,m-1]。
扩展资料:
SHA家族的五个算法,分别是SHA-1、SHA-224、SHA-256、SHA-384,和SHA-512,由美国国家安全局(NSA)所设计,并由美国国家标准与技术研究院(NIST)发布;是美国的政府标准。后四者有时并称为SHA-2。
SHA-1在许多安全协定中广为使用,包括TLS和SSL、PGP、SSH、S/MIME和IPsec,曾被视为是MD5(更早之前被广为使用的杂凑函数)的后继者。但SHA-1的安全性如今被密码学家严重质疑;
虽然至今尚未出现对SHA-2有效的攻击,它的算法跟SHA-1基本上仍然相似;因此有些人开始发展其他替代的杂凑算法。
应用
SHA-1, SHA-224, SHA-256, SHA-384 和 SHA-512 都被需要安全杂凑算法的美国联邦政府所应用,他们也使用其他的密码算法和协定来保护敏感的未保密资料。FIPS PUB 180-1也鼓励私人或商业组织使用 SHA-1 加密。Fritz-chip 将很可能使用 SHA-1 杂凑函数来实现个人电脑上的数位版权管理。
首先推动安全杂凑算法出版的是已合并的数位签章标准。
SHA 杂凑函数已被做为 SHACAL 分组密码算法的基础。
参考资料:百度百科-sha家族
Hash函数计算原理是什么
是基于高速存取的角度设计的,也是一种典型的“空间换时间”的做法。顾名思义,该数据结构能够理解为一个线性表,可是当中的元素不是紧密排列的,而是可能存在空隙。
hash算法原理
Hash Join概述 Hash join算法的一个基本思想就是根据小的row sources(称作build input,我们记较小的表为S,较大的表为B) 建立一个可以存在于hash area内存中的hash table,然后用大的row sources(称作probe input) 来探测前面所建的hash table。如果hash area内存不够大,hash table就无法完全存放在hash area内存中。针对这种情况,Oracle在连接键利用一个hash函数将build input和probe input分割成多个不相连的分区(分别记作Si和Bi),这个阶段叫做分区阶段;然后各自相应的分区,即Si和Bi再做Hash join,这个阶段叫做join阶段。如果在分区后,针对某个分区所建的hash table还是太大的话,oracle就采用nested-loops hash join。所谓的nested-loops hash join就是对部分Si建立hash table,然后读取所有的Bi与所建的hash table做连接,然后再对剩余的Si建立hash table,再将所有的Bi与所建的hash table做连接,直至所有的Si都连接完了。 Hash Join算法有一个限制,就是它是在假设两张表在连接键上是均匀的,也就是说每个分区拥有差不多的数据。但是实际当中数据都是不均匀的,为了很好地解决这个问题,oracle引进了几种技术,位图向量过滤、角色互换、柱状图,这些术语的具体意义会在后面详细介绍。 二. Hash Join原理我们用一个例子来解释Hash Join算法的原理,以及上述所提到的术语。考虑以下两个数据集。 S={1,1,1,3,3,4,4,4,4,5,8,8,8,8,10} B={0,0,1,1,1,1,2,2,2,2,2,2,3,8,9,9,9,10,10,11} Hash Join的第一步就是判定小表(即build input)是否能完全存放在hash area内存中。如果能完全存放在内存中,则在内存中建立hash table,这是最简单的hash join。如果不能全部存放在内存中,则build input必须分区。分区的个数叫做fan-out。Fan-out是由hash_area_size和cluster size来决定的。其中cluster size等于db_block_size * hash_multiblock_io_count,hash_multiblock_io_count在oracle9i中是隐含参数。这里需要注意的是fan-out并不是build input的大小/hash_ara_size,也就是说oracle决定的分区大小有可能还是不能完全存放在hash area内存中。大的fan-out导致许多小的分区,影响性能,而小的fan-out导致少数的大的分区,以至于每个分区不能全部存放在内存中,这也影响hash join的性能。 Oracle采用内部一个hash函数作用于连接键上,将S和B分割成多个分区,在这里我们假设这个hash函数为求余函数,即Mod(join_column_value,10)。这样产生十个分区,如下表. 经过这样的分区之后,只需要相应的分区之间做join即可(也就是所谓的partition pairs),如果有一个分区为NULL的话,则相应的分区join即可忽略。 在将S表读入内存分区时,oracle即记录连接键的唯一值,构建成所谓的位图向量,它需要占hash area内存的5%左右。在这里即为{1,3,4,5,8,10}。 当对B表进行分区时,将每一个连接键上的值与位图向量相比较,如果不在其中,则将其记录丢弃。在我们这个例子中,B表中以下数据将被丢弃 {0,0,2,2,2,2,2,2,9,9,9,9,9}。这个过程就是位图向量过滤。 当S1,B1做完连接后,接着对Si,Bi进行连接,这里oracle将比较两个分区,选取小的那个做build input,就是动态角色互换,这个动态角色互换发生在除第一对分区以外的分区上面。
php程序员 hash碰撞原理是什么 怎么解决
hash函数相当于,把原空间的一个数据集映射到另外一个空间 或者可以理解为把一个原文通过hash函数编程另一个文本成为密文 这就是hash加密
比如md5 任何原文都会被加密成8位或者16位密文 8位16位密文是有穷的可以穷举而原文长度不限所以理论上是无穷的 这就会出现两个或多个不同的原文md5加密后会变成相同的密文 碰撞就是找出一个或多个加密后相同密文的原文
碰撞是存在的并不能完全解决我们只能让碰撞的概率尽可能减小 那就是把映射的空间或者说加密的密文边长 密文越长组合的方式越多发生碰撞的概率就越小
hash函数的消息认证原理是什么?
利用hash函数的单向性,y=h(x),知道y求x很困难,发送方计算消息m的hash值h(m),和消息m一起发送给接收方,接收方收到消息m后,利用相同的方法计算出一个hash值h'(m)与收到的h(m)比较,如果相等认真通过,否则认证不通过!
消息认证只能判断消息是否被篡改,不能认证发送方身份的真实性!一般计算hash值的算法有MD5,SHA-1
hash函数的消息认证 过程是什么??
这就是过程啊:发送方计算消息m的hash值h(m),和消息m一起发送给接收方,接收方收到消息m后,利用相同的方法计算出一个hash值h'(m)与收到的h(m)比较,如果相等认证通过,否则认证不通过!
hash算法的数学原理是什么,如何保证尽可能少的碰撞
基于概率分析
在使用哈希函数时选择“正确”的哈希函数可以很大程度减少碰撞
比如字符串哈希可以用BKDRHash
当然也可以针对输入数据特点设计哈希算法
这个就要分情况了
请简述rfid系统中hash-chain协议的基本原理和过程,并分析此协议是否具有前向安全
RFID安全问题集用户隐私保护、企业用户商业秘密保护防范RFID系统攻击及利用RFID技术进行安全防范等面面临挑战: ① 保证用户标签拥信息未经授权访问保护用户消费习惯、行踪等面隐私 ② 避免由于RFID系统读取速度快迅速超市所商品进行扫描并跟踪变化利用窃取用户商业机密 ③ 防护RFID系统各类攻击重写标签篡改物品信息;使用特制设备伪造标签应答欺骗读写器制造物品存假相;根据RFID前向信道称性远距离窃听标签信息;通干扰RFID工作频率实施拒绝服务攻击;通发射特定电磁波破坏标签等 ④ 何RFID唯标识特性用于门禁安防、支票防伪、产品防伪等 避免RFID标签给客户带关于隐私担忧同防止用户携带安装标签产品进入市场所带混乱商家商品交付给客户都标签拆掉种疑增加系统本降低RFID标签利用率并且些场合标签拆卸
转载请注明出处51数据库 » password_hash原理 Hash算法原理
