
 隔壁家的老林
隔壁家的老林
#include"stdio.h"
#include"string.h"
void main()
{
char a[10000];
int i,j=1,k;
printf("请输入相应的文段并以回车结束:\n");
gets(a);
k=strlen(a);
for(i=0;i<k;i++)
{
if(a[i]==' ')j++;
}
printf("%d",j);
}
count是什么意思?用法是什么?
vt. 计算;认为
vi. 计数;有价值
n. 计数;计算;伯爵
count on 指望;依靠
count for 有价值,有重要性
count in 把…计算在内
count for much 关系重大;很有价值
count as 视为;算是;看成
no count 未计数
count down 倒读数,倒计时
head count [口语]人口调查;总人数;民意测验
count by 间隔数
count up 共计;把…加起来
yarn count [纺]纱线支数,丝线支数
count me in 把我算在内
body count 死亡人数统计
sperm count n. [医]精子数
bacterial count 细菌数
plate count 平板测数;平皿计数
count rate 计数率
word count n. 字数
cycle count 循环盘点;循环计数
blood count [医]血细胞计数;[医]血球计数
c语言中的word和byte是什么数据类型啊
这个都是自定义类型
一般来说 byte是单字节,也就是char或者unsigned char类型。
word是双字节,也就是short或者unsigned short.
如何在Hadoop中使用Streaming编写MapReduce
Michael G. Noll在他的Blog中提到如何在Hadoop中用Python编写MapReduce程序,韩国的gogamza在其Bolg中也提到如何用C编写MapReduce程序(我稍微修改了一下原程序,因为他的Map对单词切分使用tab键)。我合并他们两人的文章,也让国内的Hadoop用户能够使用别的语言来编写MapReduce程序。
首先您得配好您的Hadoop集群,这方面的介绍网上比较多,这儿给个链接(Hadoop学习笔记二 安装部署)。Hadoop Streaming帮 助我们用非Java的编程语言使用MapReduce,Streaming用STDIN (标准输入)和STDOUT (标准输出)来和我们编写的Map和Reduce进行数据的交换数据。任何能够使用STDIN和STDOUT都可以用来编写MapReduce程序,比如 我们用Python的sys.stdin和sys.stdout,或者是C中的stdin和stdout。
我们还是使用Hadoop的例子WordCount来做示范如何编写MapReduce,在WordCount的例子中我们要解决计算在一批文档中每一个单词的出现频率。首先我们在Map程序中会接受到这批文档每一行的数据,然后我们编写的Map程序把这一行按空格切开成一个数组。并对这个数组遍历按" 1"用标准的输出输出来,代表这个单词出现了一次。在Reduce中我们来统计单词的出现频率。
Python Code
Map: mapper.py
#!/usr/bin/env python
import sys
# maps words to their counts
word2count = {}
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words while removing any empty strings
words = filter(lambda word: word, line.split())
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word, 1)
Reduce: reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
# maps words to their counts
word2count = {}
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split()
# convert count (currently a string) to int
try:
count = int(count)
word2count[word] = word2count.get(word, 0) + count
except ValueError:
# count was not a number, so silently
# ignore/discard this line
pass
# sort the words lexigraphically;
#
# this step is NOT required, we just do it so that our
# final output will look more like the official Hadoop
# word count examples
sorted_word2count = sorted(word2count.items(), key=itemgetter(0))
# write the results to STDOUT (standard output)
for word, count in sorted_word2count:
print '%s\t%s'% (word, count)
C Code
Map: Mapper.c
#include
#include
#include
#include
#define BUF_SIZE 2048
#define DELIM "\n"
int main(int argc, char *argv[]){
char buffer[BUF_SIZE];
while(fgets(buffer, BUF_SIZE - 1, stdin)){
int len = strlen(buffer);
if(buffer[len-1] == '\n')
buffer[len-1] = 0;
char *querys = index(buffer, ' ');
char *query = NULL;
if(querys == NULL) continue;
querys += 1; /* not to include '\t' */
query = strtok(buffer, " ");
while(query){
printf("%s\t1\n", query);
query = strtok(NULL, " ");
}
}
return 0;
}
h>h>h>h>
Reduce: Reducer.c
#include
#include
#include
#include
#define BUFFER_SIZE 1024
#define DELIM "\t"
int main(int argc, char *argv[]){
char strLastKey[BUFFER_SIZE];
char strLine[BUFFER_SIZE];
int count = 0;
*strLastKey = '\0';
*strLine = '\0';
while( fgets(strLine, BUFFER_SIZE - 1, stdin) ){
char *strCurrKey = NULL;
char *strCurrNum = NULL;
strCurrKey = strtok(strLine, DELIM);
strCurrNum = strtok(NULL, DELIM); /* necessary to check error but.... */
if( strLastKey[0] == '\0'){
strcpy(strLastKey, strCurrKey);
}
if(strcmp(strCurrKey, strLastKey)){
printf("%s\t%d\n", strLastKey, count);
count = atoi(strCurrNum);
}else{
count += atoi(strCurrNum);
}
strcpy(strLastKey, strCurrKey);
}
printf("%s\t%d\n", strLastKey, count); /* flush the count */
return 0;
}
h>h>h>h>
首先我们调试一下源码:
chmod +x mapper.py
chmod +x reducer.py
echo "foo foo quux labs foo bar quux" | ./mapper.py | ./reducer.py
bar 1
foo 3
labs 1
quux 2
g++ Mapper.c -o Mapper
g++ Reducer.c -o Reducer
chmod +x Mapper
chmod +x Reducer
echo "foo foo quux labs foo bar quux" | ./Mapper | ./Reducer
bar 1
foo 2
labs 1
quux 1
foo 1
quux 1
你可能看到C的输出和Python的不一样,因为Python是把他放在词典里了.我们在Hadoop时,会对这进行排序,然后相同的单词会连续在标准输出中输出.
在Hadoop中运行程序
首先我们要下载我们的测试文档wget http://www.gutenberg.org/dirs/etext04/7ldvc10.txt.我们把文档存放在/tmp/doc这个目录下.拷贝测试文档到HDFS中.
bin/hadoop dfs -copyFromLocal /tmp/doc doc
运行 bin/hadoop dfs -ls doc 看看拷贝是否成功.接下来我们运行我们的MapReduce的Job.
bin/hadoop jar /home/hadoop/contrib/hadoop-0.15.1-streaming.jar -mapper /home/hadoop/Mapper\
-reducer /home/hadoop/Reducer -input doc/* -output c-output -jobconf mapred.reduce.tasks=1
additionalConfSpec_:null
null=@@@userJobConfProps_.get(stream.shipped.hadoopstreaming
packageJobJar: [] [/home/msh/hadoop-0.15.1/contrib/hadoop-0.15.1-streaming.jar] /tmp/streamjob60816.jar tmpDir=null
08/03/04 19:03:13 INFO mapred.FileInputFormat: Total input paths to process : 1
08/03/04 19:03:13 INFO streaming.StreamJob: getLocalDirs(): [/home/msh/data/filesystem/mapred/local]
08/03/04 19:03:13 INFO streaming.StreamJob: Running job: job_200803031752_0003
08/03/04 19:03:13 INFO streaming.StreamJob: To kill this job, run:
08/03/04 19:03:13 INFO streaming.StreamJob: /home/msh/hadoop/bin/../bin/hadoop job -Dmapred.job.tracker=192.168.2.92:9001 -kill job_200803031752_0003
08/03/04 19:03:13 INFO streaming.StreamJob: Tracking URL: http://hadoop-master:50030/jobdetails.jsp?jobid=job_200803031752_0003
08/03/04 19:03:14 INFO streaming.StreamJob: map 0% reduce 0%
08/03/04 19:03:15 INFO streaming.StreamJob: map 33% reduce 0%
08/03/04 19:03:16 INFO streaming.StreamJob: map 100% reduce 0%
08/03/04 19:03:19 INFO streaming.StreamJob: map 100% reduce 100%
08/03/04 19:03:19 INFO streaming.StreamJob: Job complete: job_200803031752_0003
08/03/04 19:03:19 INFO streaming.StreamJob: Output: c-output
bin/hadoop jar /home/hadoop/contrib/hadoop-0.15.1-streaming.jar -mapper /home/hadoop/mapper.py\
-reducer /home/hadoop/reducer.py -input doc/* -output python-output -jobconf mapred.reduce.tasks=1
additionalConfSpec_:null
null=@@@userJobConfProps_.get(stream.shipped.hadoopstreaming
packageJobJar: [] [/home/hadoop/hadoop-0.15.1/contrib/hadoop-0.15.1-streaming.jar] /tmp/streamjob26099.jar tmpDir=null
08/03/04 19:05:40 INFO mapred.FileInputFormat: Total input paths to process : 1
08/03/04 19:05:41 INFO streaming.StreamJob: getLocalDirs(): [/home/msh/data/filesystem/mapred/local]
08/03/04 19:05:41 INFO streaming.StreamJob: Running job: job_200803031752_0004
08/03/04 19:05:41 INFO streaming.StreamJob: To kill this job, run:
08/03/04 19:05:41 INFO streaming.StreamJob: /home/msh/hadoop/bin/../bin/hadoop job -Dmapred.job.tracker=192.168.2.92:9001 -kill job_200803031752_0004
08/03/04 19:05:41 INFO streaming.StreamJob: Tracking URL: http://hadoop-master:50030/jobdetails.jsp?jobid=job_200803031752_0004
08/03/04 19:05:42 INFO streaming.StreamJob: map 0% reduce 0%
08/03/04 19:05:48 INFO streaming.StreamJob: map 33% reduce 0%
08/03/04 19:05:49 INFO streaming.StreamJob: map 100% reduce 0%
08/03/04 19:05:52 INFO streaming.StreamJob: map 100% reduce 100%
08/03/04 19:05:52 INFO streaming.StreamJob: Job complete: job_200803031752_0004
08/03/04 19:05:52 INFO streaming.StreamJob: Output: python-output
当Job提交后我们还能够在web的界面http://localhost:50030/看到每一个工作的运行情况。
当Job工作完成后我们能够在c-output和python-output看到一些文件
bin/hadoop dfs -ls c-output
输入下面的命令我们能够看到我们运行完MapReduce的结果
bin/hadoop dfs -cat c-output/part-00000
用Hadoop Streaming运行MapReduce会比较用Java的代码要慢,因为有两方面的原因:
使用 Java API >> C Streaming >> Perl Streaming 这样的一个流程运行会阻塞IO.
不像Java在运行Map后输出结果有一定数量的结果集就启动Reduce的程序,用Streaming要等到所有的Map都运行完毕后才启动Reduce
如果用Python编写MapReduce的话,另一个可选的是使用Jython来转编译Pyhton为Java的原生码.另外对于C程序员更好的选择是使用Hadoop新的C++ MapReduce API Pipes来编写.不管怎样,毕竟Hadoop提供了一种不使用Java来进行分布式运算的方法.
下面是从http://www.lunchpauze.com/2007/10/writing-hadoop-mapreduce-program-in-php.html页面中摘下的用php编写的MapReduce程序,供php程序员参考:
Map: mapper.php
#!/usr/bin/php
$word2count = array();
// input comes from STDIN (standard input)
while (($line = fgets(STDIN)) !== false) {
// remove leading and trailing whitespace and lowercase
$line = strtolower(trim($line));
// split the line into words while removing any empty string
$words = preg_split('/\W/', $line, 0, PREG_SPLIT_NO_EMPTY);
// increase counters
foreach ($words as $word) {
$word2count[$word] += 1;
}
}
// write the results to STDOUT (standard output)
// what we output here will be the input for the
// Reduce step, i.e. the input for reducer.py
foreach ($word2count as $word => $count) {
// tab-delimited
echo $word, chr(9), $count, PHP_EOL;
}
?>
Reduce: mapper.php
#!/usr/bin/php
$word2count = array();
// input comes from STDIN
while (($line = fgets(STDIN)) !== false) {
// remove leading and trailing whitespace
$line = trim($line);
// parse the input we got from mapper.php
list($word, $count) = explode(chr(9), $line);
// convert count (currently a string) to int
$count = intval($count);
// sum counts
if ($count > 0) $word2count[$word] += $count;
}
// sort the words lexigraphically
//
// this set is NOT required, we just do it so that our
// final output will look more like the official Hadoop
// word count examples
ksort($word2count);
// write the results to STDOUT (standard output)
foreach ($word2count as $word => $count) {
echo $word, chr(9), $count, PHP_EOL;
}
?>
作者:马士华 发表于:2008-03-05
excel中的count函数怎么用
1、COUNT函数是计数函数。COUNT函数可以引用各种类型数据的参数1 到 30个。可以是单元格,数字、日期等,但必须是数字形式

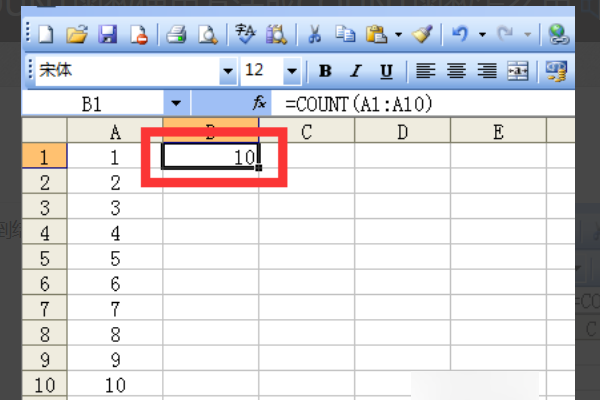
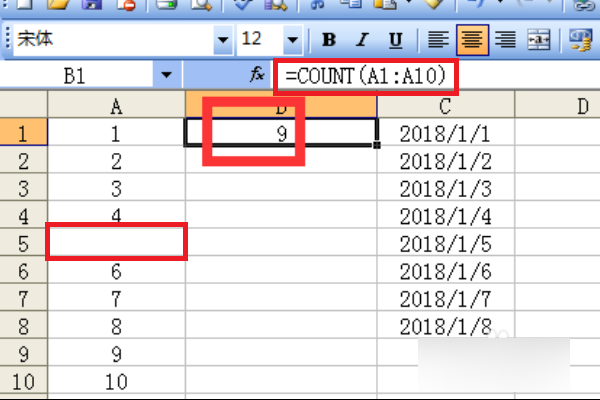
2、输入10个数字,再用公式=COUNT(A1:A10),计算几个单元格有数,回车之后,得到结果
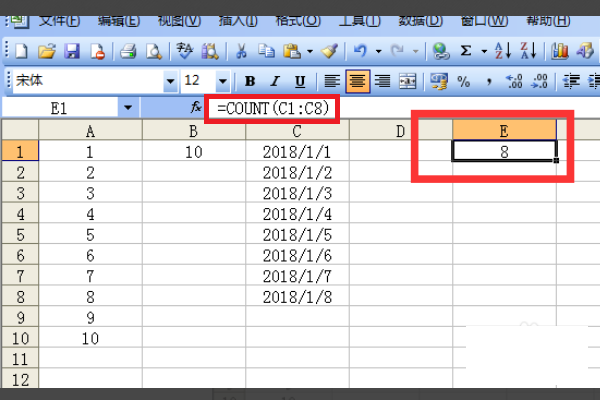
3、输入8个日期,再输入公式=COUNT(C1:C8),计算个数,回车之后,得到结果
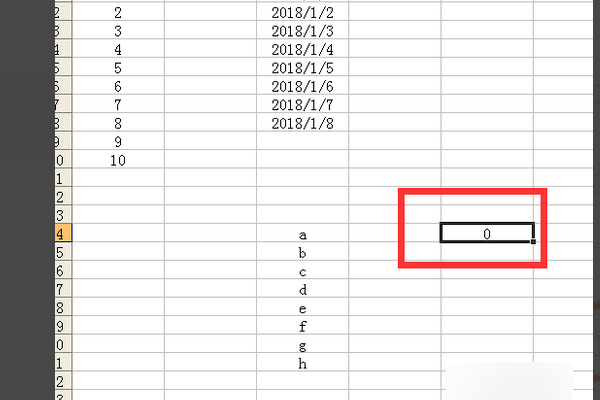
4、输入8个字母,再输入公式=count(C14:C21),计算个数,回车之后,得到结果0,没有统计出数字来,说明count函数对字母无效
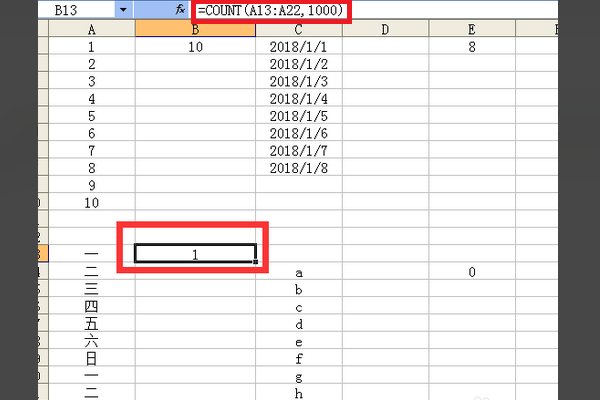
5、在公式=COUNT(A13:A22,1000)加上1000,回车之后,得到结果1,说明count对汉字无效,对公式里的数字有效,被计录为1
6、把数字删除一个再输入公式=COUNT(A1:A10)计算个数,回车之后,得到结果,说明count自动忽略空单元格
sql count问题
这是根据个人实际验证过的:
-- 1 建表
create table a
(
a varchar2(3),
b varchar2(3)
)
-- 2 插入测试数据
Insert into A
(A, B)
Values
('a', 'b');
Insert into A
(A, B)
Values
('a', 'b');
Insert into A
(A, B)
Values
('c', 'd');
Insert into A
(A, B)
Values
('c', 'e');
Insert into A
(A, B)
Values
('c', 'e');
Insert into A
(A, B)
Values
('c', 'e');
COMMIT;
-- 3 验证查询结果 只对 b 进行频率统计
select s.a,t.b,t.times
from a s,
(select b,count(*) times
from a
group by b) t
where s.b = t.b
group by s.a,t.b,t.times
-- 4 对 (a b) 的出现频率进行统计
select a,b,count(*) times
from a
group by a,b
-- 将结果插入到 b表中
insert into b
(
a,b,times
)
select a,b,count(*) times
from a
group by a,b
如果满意答案,请采纳为最佳答案,谢谢~~
android驱动开发好了,怎么调试
本文用《Android深度探索(卷1):HAL与驱动开发》的随书源代码为例详细说明如何配置Android驱动开发和测试环境,并且如何使用源代码中的build.sh脚本文件在各种平台(Ubuntu Linux、Android模拟器和S3C6410开发板)上编译、安装和测试Linux驱动。建议读者使用Ubuntu Linux12.04或更高版本实验本文的方法。最好用root账号登录Linux。
一、安装交叉编译器
如果只是在Ubuntu Linux上测试Linux驱动就不需要安装交叉编译器了,但要在Android模拟器或S3C6410开发板上进行测试,就必须安装交叉编译器。
首先下载交叉编译器(分卷压缩)
下载后解压,会发现有两个tgz文件,可以将这两个文件放到/root/compilers目录中,在Linux终端进入该目录,执行如下命令安装交叉编译器。
[plain] view plain copy
# tar zxvf arm-linux-gcc-4.3.2.tgz -C /
# tar jxvf arm-none-linux-gnueabi-arm-2008q3-72-for-linux.tar.bz2 -C /
二、编译和测试Linux内核
这里的Linux内核有两个,一个是goldfish,也就是Android模拟器使用的Linux内核、另外一个是S3C6410开发板使用的Linux内核(Linux2.6.36)。读者首先要下载这两个Linux内核。
Android模拟器用的Linux内核源代码(分卷压缩)
用于S3C6410开发板的Linux内核源代码(分卷压缩)
分卷1
分卷2
由于随书代码中的word_count驱动已经在goldfish和linux2.6.36中分别建立了符号链接,以便在编译linux内核时同时也会编译word_count驱动,所以linux内核与源代码目录应与作者机器上的目录相同。也就是两个linux内核目录与源代码目录如下:
linux内核目录
/root/kernel/goldfish
/root/kernel/linux_kernel_2.6.36
源代码目录
/root/drivers
注意/root/drivers目录下就直接是每一章的源代码了,例如/root/drivers/ch06、/root/drivers/ch07
现在需要将/usr/local/arm/arm-none-linux-gnueabi/bin路径加到Linux的PATH环境变量中(不会加的上网查,这是Linux的基本功)
最后进入/root/compilers/goldfish目录,执行make命令编译linux内核,如果完全编译,大概20分钟左右。编译完成后,会在/root/kernel/goldfish/arch/arm/boot目录中生成一个zImage文件,代码1.7MB,这就是用于Android模拟器的Linux内核文件。
三、编译Linux驱动
现在来编译随书光盘的驱动程序,这里以word_count驱动为例。在Linux终端进入/root/drivers/ch06/word_count目录。先别忙着编译。首先要设置打开/root/drivers/common.sh文件,修改第一行UBUNTU_KERNEL_PATH变量值为自己机器上安装的Ubuntu Linux内核路径,只要执行“ls /usr/src”命令即可查看当前机器可用的linux内核。如可以设置下面的路径。
UBUNTU_KERNEL_PATH=/usr/src/linux-headers-3.2.0-23-generic
剩下的两个(S3C6410_KERNEL_PATH和/root/kernel/goldfish)只要按着前面的路径解压Linux内核源代码,就不用设置了。
在word_count目录中执行“source build.sh”命令,会允许选择在哪个平台上编译驱动,直接按回车会在Ubuntu Linux上编译。如果编译成功,会发现当前目录多一个word_count.ko文件(驱动文件)。
现在来编译S3C6410上运行的word_count驱动。先别忙,在编译之前,需要Android中的adb命令。因为build.sh足够只能,在编译完后,如果有多个Android设备连接到PC,会允许用户选择上传到哪个设备装载,这里需要选择S3C6410开发板,然后会直接上传到开发板上,如图1所示。
可以直接使用adb shell命令进入开发板,也可以使用/root/drivers/shell.sh脚本完成同样的工作,只是后者如果有多个android设备,会允许用选择,而不是输入相应的设备ID。使操作更方便。在/root/drivers目录中提供了很多这样的脚本(shell.sh、push.sh、pull.sh等),这些脚本都会允许用户选择操作的Android设备。
我们通常使用Android SDK中的adb命令,到官方网站下载装载linux版本的Android SDK,然后将<AndroidSDK根目录> /platform-tools加到PATH环境变量中。
现在再次执行“source build.sh”命令,选择第2项(S3C6410开发板),如果系统没找到开发板,需要将USB线拔下重插一下。然后就可以进入开发板的终端,输入lsmod命令查看驱动的安装情况了。
如果在模拟器上测试,选第3项。具体测试的方法请参见书中相应的章节。
四、测试Linux驱动
测试word_count驱动的方法很多,通过命令行测试的方法请参见书中相应的章节,在word_count目录中有一个test_word_count程序,通过执行如下的命令可以测试word_count驱动,编译test_word_count.c程序的方法书中已详细描述。
test_word_count “abc bb cc”
上面的命令会输出单词数为3。
如果要编译Android HAL,需要Android源代码。购买S3C6410开发板时商家通常会带一些光盘,里面有用于开发板的Android源代码,如果商家没给光盘,别忘了要哦!
用c语言编写一个小程序,可以读入一个英文的文本文件,显示这个文件,并统计这个文件有多少个字符,多少
#include <stdio.h>
#include <string.h>
#include <img alt="搜索" src="http://www.51sjk.com/Upload/Articles/1/0/93/93316_20200419220312310.png" id="selectsearch-icon"><ctype.h>
int main()
{
FILE *fp = NULL;
char read_buf = 0;
int char_count = 0;
int word_count = 0;
int tab_count = 0;
int blank_count = 0;
int paragraph_count = 0;
int word_start = 0;
fp = fopen("English_file.txt", "r");
if (fp == NULL)
{
printf("Can't open the file.\n");
return -1;
}
printf("The following is the file content: \n");
while (!feof(fp))
{
read_buf = fgetc(fp);
printf("%c", read_buf);
if (isalpha(read_buf))
{
char_count++;//字母
if (word_start == 0)
{
word_start = 1;
}
}
else//非字母
{
if (word_start == 1)
{
word_count++;//单词
word_start = 0;
}
switch (read_buf)
{
case '\t'://tab
tab_count++;
break;
case '\040'://空格
blank_count++;
break;
case '.':
case '!':
case '?':
case ':':
read_buf = fgetc(fp); //再取一个字符
printf("%c", read_buf);
//如果是回车或者换行就表示一个段落结束了
if ( read_buf == '\r' || read_buf == '\n' )
{
paragraph_count++ ; //段落
}
break;
default:
break;
}
}
}
printf("\n");
printf("tab_count: %d\n", tab_count);
printf("blank_count: %d\n", blank_count);
printf("char_count: %d\n", char_count);
printf("word_count: %d\n", word_count);
printf("paragraph_count: %d\n", paragraph_count);
return 0;
}
转载请注明出处51数据库 » wordcountc 关于C编程countword
