
 重溶日月-
重溶日月-
操作步骤:
1、在电脑中安装spss统计软件;
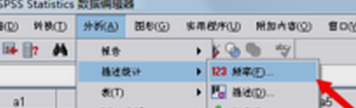
2、在“分析”下面的“描述统计”中,选择“频率”,点击进入;
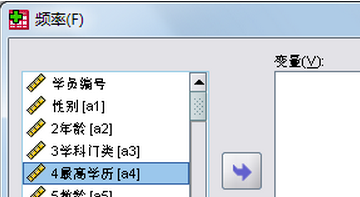
3、弹出一个对话框,选择要画图分析的变量,选中它,并点击中间的箭头就可以添加到右边这个框中;
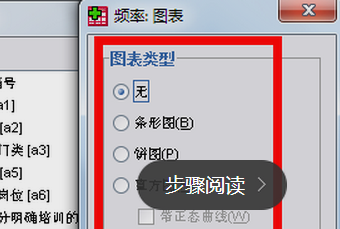
4、点击界面上的“图表”,进入到图标类型选择界面,可以选择直方图,也可以选择条形图或饼图等,点击“继续”;
5、继续之后,就回到了原先的界面上,接下来点击“确定”即可;
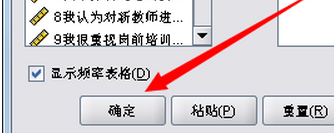
6、确认之后,会弹出一个输出窗口,系统自动画出了表格和饼图。
如何用SPSS绘制直方图
菜单里面,选择,分析(Analyze)-描述统计(Descriptive Statistics)-频率(Frequencies)
弹出来菜单,变量(Variable) 里面选择你要作图的变量
右边,统计(Statistics)选择上你要统计的量
图标(Charts)选择上直方图(Histogram)
之后输出里面就有你要的直方图了
如何使用spss绘制曲线图
绘制线图的具体操作步骤如下:
打开【图形】(Graphs)菜单,选择【旧对话框】(Legacy Dialogs)命令下的【线图】(Line Charts)命令,SPSS将弹出"线图"(Line Charts)导航对话框,如下图所示。
在该导航对话框中,用户可以选择线图的类型,并定义线图中数据的表达方式。
SPSS将线图大致分为3种类型:
(1)简单(Simple):单线图,一个图形中只有一条水平走向的折线;
(2)多线线图(Multiple):多线图,一个图形中有多条水平走向的折线;
(3)垂直线图(Drop-line):垂线图,一个图形中有多组水平走向的数据,但在水平方向上不予以连接,而只是在垂直方向上将同一时间点的数据予以连接。
图表中的数据为(Data in Chart are)栏:用户可以选择以下的条形图中的数据表达类型:
个案组摘要(Summaries for groups of cases):用分类值作图,线图中每一条线代表观测量的一个分类;
各个变量的摘要(Summaries of separate variables):用变量值作图,线图中每一条线代表一个变量;
个案值(Values of individual cases):用单元值作图,线图中每一条线代表一个观察值。
通过以上3个线图类型和3个数据表达类型的不同搭配,SPSS可以生成9种不同的线图。本书以用户选择"简单"线图和"个案组摘要"为例,阐述线图的绘制步骤。
单击【定义】(Define)按钮,进入正式的定义对话框"定义简单线图:个案组摘要"(Define Simple Line:Summaries for groups of cases)对话框,如图所示。根据用户所选的线图类型和数据表达类型的不同,出现的对话框名称也不同。
在该对话框中,用户首先需要指定绘图变量,即通过单击 按钮从左边原变量中选择多个需要绘制折线图的变量进入右边的"线的表征"(Lines Represent)中。绘图变量的数值将在线图的纵轴上表示。
同时,用户需要指定分类变量。用户可以选择以"个案数"(Case number),即观测量的编号作为分类变量,也可以选中"变量"(Variable)选项,然后单击 按钮选择一个变量作为分类变量。例如,在时间序列分析中,用户就可以将时间变量作为分类变量。分类变量的数值将在线图的横轴上表示。
本对话框的其他部分及单击【标题】(Title)按钮所弹出的"标题"(Title)对话框都与"定义简单条形图:个案组摘要"(Define Simple Bar:Summaries for Groups of Cases)对话框完全相同,此处不再赘述。
在"定义简单线图:个案组摘要"主对话框中,单击【确定】(OK)按钮,即可在结果输出窗口中得到线图。
怎么使用SPSS软件
当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量、数据录入、统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.
Spss处理:
第一步:定义变量
大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View, Variable View两个标签,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、label(变量标签) 、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类).
我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:
1.请问你的年龄属于下面哪一个年龄段( )?
A:20—29 B:30—39 C:40—49 D:50--59
那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, width宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。Values用于定义具体变量值的标签,单击Value框右半部的省略号,会弹出变量值标签对话框,在第一个文本框里输入1,第二个输入20—29,然后单击添加即可.同样道理我们可做如下设置,即1=20—29、2=30—39、3=40—49、4=50--59;Missing,用于定义变量缺失值, 单击missing框右侧的省略号,会弹出缺失值对话框, 界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值”,最多可以定义3个值;最后一项为“缺失值范围加可选的一个缺失值”,在此我们不设置缺省值,所以选中第一项如图;Colomns,定义显示列宽,可自己根据实际情况设置;Align,定义显示对齐方式,有居左、居右、居中三种方式;Measure,定义变量类型是连续、有序分类还是无序分类。
以上为问卷中常见的单项选择题型的变量设置,下面将对一些特殊情况的变量设置也作一下说明.
1.开放式题型的设置:诸如你所在的省份是_____这样的填空题即为开放题,设置这些变量的时候只需要将Value 、Missing两项不设置即可.
2.多选题的变量设置:这类题型的设置有两种方法即多重二分法和多重分类法,在这里我们只对多重二分法进行介绍.这种方法的基本思想是把该题每一个选项设置成一个变量,然后将每一个选项拆分为两个选项项,即选中该项和不选中该项.现在举例来说明在spss中的具体操作.比如如下一例:
请问您通常获取新闻的方式有哪些( )
1 报纸 2 杂志 3 电视 4 收音机 5 网络
在spss中设置变量时可为此题设置五个变量,假如此题为问卷第三题,那么变量名分别为3_1、3_2、3_3、3_4、3_5,然后每一个选项有两个选项选中和不选中,只需在Value一项中为每一个变量设置成1=选中此项、0=不选中此项即可.
使用该窗口,我们可以把一个问卷中的所有问题作为变量在这个窗口中一次定义。
到此,我们的定义变量的工作就基本上可以结束了.下面我们要作就是数据的录入了.首先,我们要回到数据录入窗口,这很简单,只要我们点击软件左下方的Data View标签就可以了.
第二步:数据录入
Spss数据录入有很多方式,大致有一下几种:
1.读取SPSS格式的数据
2.读取Excel等格式的数据
3.读取文本数据(Fixed和Delimiter)
4.读取数据库格式数据(分如下两步)
(1)配置ODBC (2)在SPSS中通过ODBC和数据库进行
但是对于问卷的数据录入其实很简单,只要在spss的数据录入窗口中直接输入就可以了,只是在这里有几点注意的事项需要说明一下.
1. 在数据录入窗口,我们可以看到有一个表格,这个表格中的每一行代表一份问卷,我们也称为一个个案.
2. 在数据录入窗口中,我们可以看到表格上方出现了1、2、3、4、5…….的标签名,这其实是我们在第一步定义变量中,我们为问卷的每一个问题取的变量名,即1代表第一题,2代表第二题.以次类推.我们只需要在变量名下面输入对应问题的答案即可完成问卷的数据录入.比如上述年龄段查询的例题,如果问卷上勾选了A答案,我们在1下面输入1就行了(不要忘记我们通常是用1、2、3、4来代替A、B、C、D的).
3.我们知道一行代表一份问卷,所以有几分问卷,就要有几行的数据.
在数据录入完成后,我们要做的就是我们的关键部分,即问卷的统计分析了,因为这时我们已经把问卷中的数据录入我们的软件中了.
第三步:统计分析
有了数据,可以利用SPSS的各种分析方法进行分析,但选择何种统计分析方法,即调用哪个统计分析过程,是得到正确分析结果的关键。这要根据我们的问卷调查的目的和我们想要什么样的结果来选择.SPSS有数值分析和作图分析两类方法.
1.作图分析:
在SPSS中,除了生存分析所用的生存曲线图被整合到Analyze菜单中外,其他的统计绘图功能均放置在graph菜单中。该菜单具体分为以下几部分::
(1)Gallery:相当于一个自学向导,将统计绘图功能做了简单的介绍,初学者可以通过它对SPSS的绘图能力有一个大致的了解。
(2)Interactive:交互式统计图。
(3)Map:统计地图。
(4)下方的其他菜单项是我们最为常用的普通统计图,具体来说有:
条图
散点图
线图
直方图
饼图
面积图
箱式图
正态Q-Q图
正态P-P图
质量控制图
Pareto图
自回归曲线图
高低图
交互相关图
序列图
频谱图
误差线图
作图分析简单易懂,一目了然,我们可根据需要来选择我们需要作的图形,一般来讲,我们较常用的有条图,直方图,正态图,散点图,饼图等等,具体操作很简单,大家可参阅相关书籍,作图分析更多情况下是和数值分析相结合来对试卷进行分析的,这样的效果更好.
2.数值分析:
SPSS 数值统计分析过程均在Analyze菜单中,包括:
(1)、Reports和Descriptive Statistics:又称为基本统计分析.基本统计分析是进行其他更深入的统计分析的前提,通过基本统计分析,用户可以对分析数据的总体特征有比较准确的把握,从而选择更为深入的分析方法对分析对象进行研究。Reports和Descriptive Statistics命令项中包括的功能是对单变量的描述统计分析。
Descriptive Statistics包括的统计功能有:
Frequencies(频数分析):作用:了解变量的取值分布情况
Descriptives(描述统计量分析):功能:了解数据的基本统计特征和对指定的变量值进行标准化处理
Explore(探索分析):功能:考察数据的奇异性和分布特征
Crosstabs(交叉分析):功能:分析事物(变量)之间的相互影响和关系
Reports包括的统计功能有:
OLAP Cubes(OLAP报告摘要表):功能: 以分组变量为基础,计算各组的总计、均值和其他统计量。而输出的报告摘要则是指每个组中所包含的各种变量的统计信息。
Case Summaries(观测量列表):察看或打印所需要的变量值
Report Summaries in Row:行形式输出报告
Report Summaries in Columns:列形式输出报告
(2)、Compare Means(均值比较与检验):能否用样本均值估计总体均值?两个变量均值接近的样本是否来自均值相同的总体?换句话说,两组样本某变量均值不同,其差异是否具有统计意义?能否说明总体差异?这是各种研究工作中经常提出的问题。这就要进行均值比较。
以下是进行均值比较及检验的过程:
MEANS过程:不同水平下(不同组)的描述统计量,如男女的平均工资,各工种的平均工资。目的在于比较。术语:水平数(指分类变量的值数,如sex变量有2个值,称为有两个水平)、单元Cell(指因变量按分类变量值所分的组)、水平组合
T test 过程:对样本进行T检验的过程
单一样本的T检验:检验单个变量的均值是否与给定的常数之间存在差异。
独立样本的T检验:检验两组不相关的样本是否来自具有相同均值的总体(均值是否相同,如男女的平均收入是否相同,是否有显著性差异)
配对T检验:检验两组相关的样本是否来自具有相同均值的总体(前后比较,如训练效果,治疗效果)
One-Way ANOVA:一元(单因素)方差分析,用于检验几个(三个或三个以上)独立的组,是否来自均值相同的总体。
(3)、ANOVA Models(方差分析):方差分析是检验多组样本均值间的差异是否具有统计意义的一种方法。例如:医学界研究几种药物对某种疾病的疗效;农业研究土壤、肥料、日照时间等因素对某种农作物产量的影响;不同饲料对牲畜体重增长的效果等,都可以使用方差分析方法去解决
(4)、Correlate(相关分析):它是研究变量间密切程度的一种常用统计方法,常用的相关分析有以下几种:
1、线性相关分析:研究两个变量间线性关系的程度。用相关系数r来描述。
2、偏相关分析:它描述的是当控制了一个或几个另外的变量的影响条件下两个变量间的相关性,如控制年龄和工作经验的影响,估计工资收入与受教育水平之间的相关关系
3、相似性测度:两个或若干个变量、两个或两组观测量之间的关系有时也可以用相似性或不相似性来描述。相似性测度用大值表示很相似,而不相似性用距离或不相似性来描述,大值表示相差甚远
(5)、Regression(回归分析):功能:寻求有关联(相关)的变量之间的关系在回归过程中包括:Liner:线性回归;Curve Estimation:曲线估计;Binary Logistic: 二分变量逻辑回归;Multinomial Logistic:多分变量逻辑回归;Ordinal 序回归;Probit:概率单位回归;Nonlinear:非线性回归;Weight Estimation:加权估计;2-Stage Least squares:二段最小平方法;Optimal Scaling 最优编码回归;其中最常用的为前面三个.
(6)、Nonparametric Tests(非参数检验):是指在总体不服从正态分布且分布情况不明时,用来检验数据资料是否来自同一个总体假设的一类检验方法。由于这些方法一般不涉及总体参数故得名。
非参数检验的过程有以下几个:
1.Chi-Square test 卡方检验
2.Binomial test 二项分布检验
3.Runs test 游程检验
4.1-Sample Kolmogorov-Smirnov test 一个样本柯尔莫哥洛夫-斯米诺夫检验
5.2 independent Samples Test 两个独立样本检验
6.K independent Samples Test K个独立样本检验
7.2 related Samples Test 两个相关样本检验
8.K related Samples Test 两个相关样本检验
(7)、Data Reduction(因子分析)
(8)、Classify(聚类与判别)等等
以上就是数值统计分析Analyze菜单下几项用于分析的数值统计分析方法的简介,在我们的变量定义以及数据录入完成后,我们就可以根据我们的需要在以上几种分析方法中选择若干种对我们的问卷数据进行统计分析,来得到我们想要的结果.
第四步:结果保存
我们的spss软件会把我们统计分析的多有结果保存在一个窗口中即结果输出窗口(output),由于spss软件支持复制和粘贴功能,这样我们就可以把我们想要的结果复制、粘贴到我们的报告中,当然我们也可以在菜单中执行file->save来保存我们的结果,一般情况下,我们建议保存我们的数据,结果可不保存.因为只要有了数据,如果我们想要结果的,我们可以随时利用数据得到结果.
总结:
以上便是spss处理问卷的四个步骤,四个步骤结束后,我们需要spss软件做的工作基本上也就结束了,接下来的任务就是写我们的统计报告了.值得一提的是.spss是一款在社会统计学应用非常广泛的统计类软件,学好它将对我们以后的工作学习产生很大的意义和作用.
如何用spss 做卡方检验
1、建立数据文件。对新手而言此步最关键。
打开软件,“新数据集”, 假如是一个两列三行的数据,在Excel中原始表可以是两列并立,共3行数字,而此时在SPSS中新数据集建成后则一般为单列6行数字。
在变量视图中设置变量为第一步,假如在Excel中是一个两列三行的数据,在Excel中两列题头分别为“不突出子宫”“突出子宫”,在Excel中三行分别为“粘连型”“植入型”“穿透型”,则在SPSS中需设置3个变量,第一变量名称填为“位置”,类型选“字符串”,测量选“名义”; 第二变量名称填为“类型”,类型选“字符串”,测量选“名义”; 第三变量名称填为“数值”,类型选“数值”,测量选“度量”;

(图1)
在数据视图中开始输入数据,在第一列位置下第1、2行分别输入“不突出”“突出”,第3、4行;5、6行同1、2行;在第二列类型下第1、2行输入“粘连型”,3、4行输入“ 植入型”,5、6行输入“ 穿透型”;在第三列数值下输入各类数据的具体值。
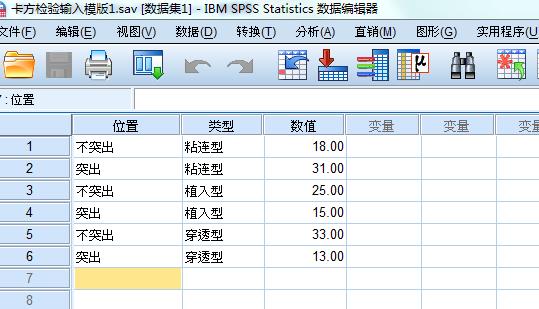
至此,数据集建立完毕。
2、单击主菜单“数据"-”加权个案“,打开加权个案对话框。从左边源变量选择“数值”作为权变量,将其选入“频率变量:”框中,单击”确定“按钮,执行加权命令。
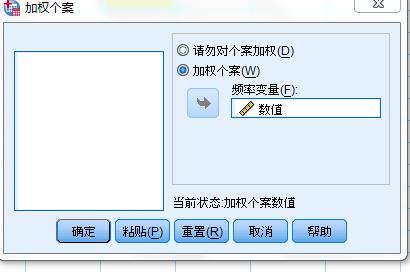
加权后此行数值作为个数出现,如35表示有35例;而不加权则此行数值作为单一数值,如35cm之类。
3、单击主菜单中的“分析”-“描述统计”-“交叉表”,打开对话框。
将左边源对话框中的“位置”作为行变量调入“行:”下的矩形框;“类型”作为列变量调入“列:”下矩形框。
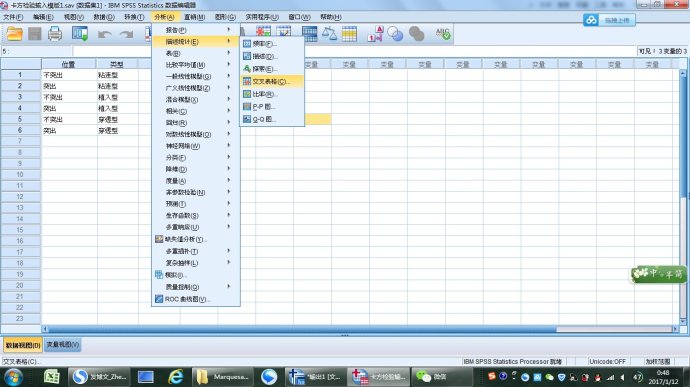
4、单击“交叉表”对话框中的“统计量”选项,选中“卡方”,单击“继续”,返回到“交叉表”对话框。
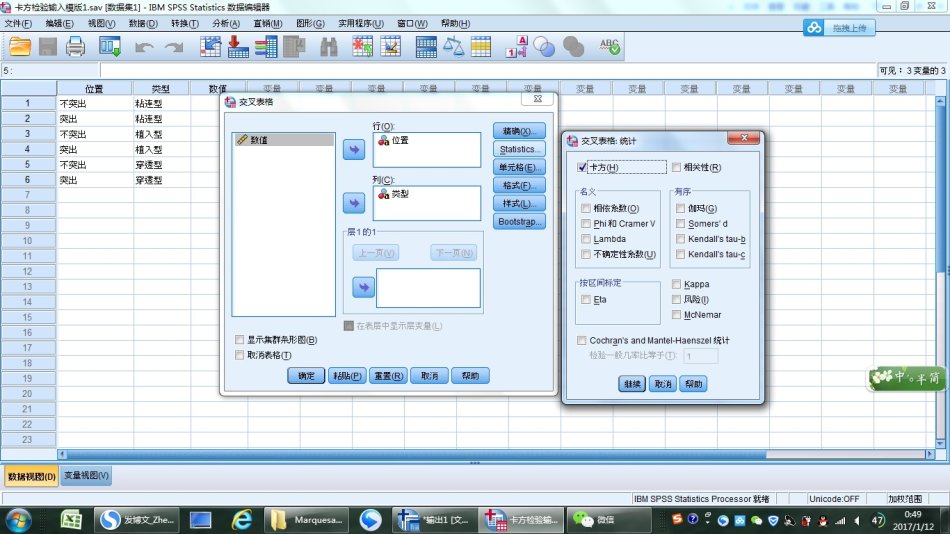
5、单击"单元格"选项,在计数下激活“期望值”,在百分比下激活“行”,单击“继续”,返回到“交叉表”对话框。
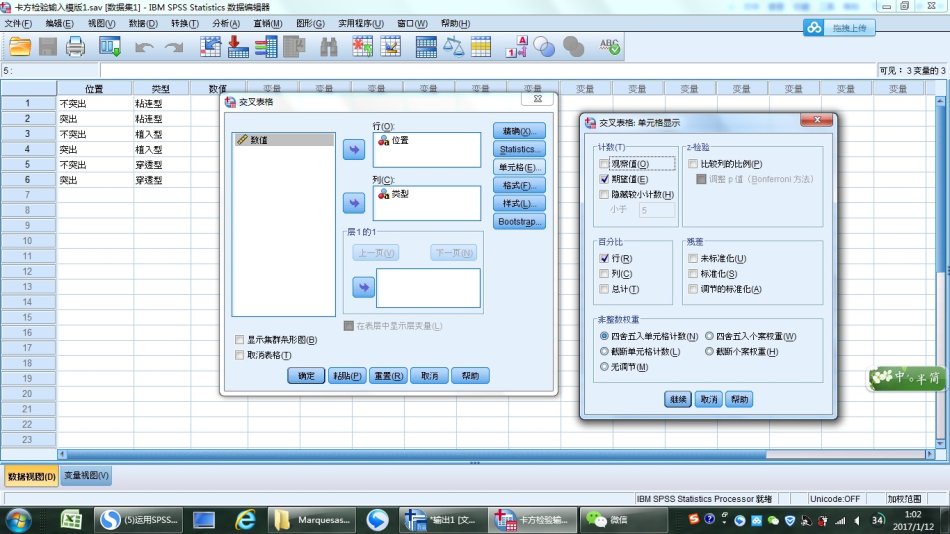
6、在“交叉表”对话框中,单击"确定"按钮,即可得输出结果。
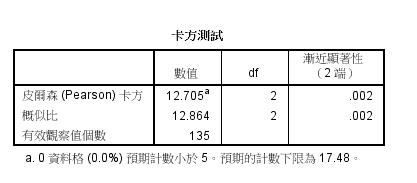
7、卡方检验结果:主要看pearson卡方检验行,pearson卡方数值即为卡方值(如下的12.705),渐近显著性(sig)值即为P值(如下的0.002),小于0.05时认为不同位置对不同类型的胎盘判断有显著的差别。
扩展资料:
SPSS(Statistical Product and Service Solutions),“统计产品与服务解决方案”软件。最初软件全称为“社会科学统计软件包”(SolutionsStatistical Package for the Social Sciences),但是随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于2000年正式将英文全称更改为“统计产品与服务解决方案”,这标志着SPSS的战略方向正在做出重大调整。
SPSS为IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,有Windows和Mac OS X等版本。
1984年SPSS总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域。世界上许多有影响的报刊杂志纷纷就SPSS的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价。
参考资料:百度百科-spss
spss软件聚类分析怎么用,从输入数据到结果,树状图结果。整个操作怎么进行。需要基本思路。
基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法)
层次聚类法和迭代聚类法的主要区别在于:层次聚类法的聚类结果受奇异值的影响非常大,且聚类过程是单方向的,一旦某个样本进入某一类,就不可能从该类出来,再归入其他的类;迭代聚类法的聚类结果受奇异值和不合适的聚类变量的影响较小,对于不合适的初始聚类可以进行反复调整,但其缺点是聚类结果对初始聚类非常敏感,而且它也只能得到局部最优解.
(一)层次聚类
Analyze--> C1assify-->Hierachical Cluster
在“C1uster”组中选择聚类类型:要进行变量聚类选择指定“Vanables”;要进行观测量聚类指定“Cases”。
指定参与分析的变量,将选定的变量通过按钮箭头转移到箭头按钮右侧的“Variable[s]:”矩形框中;将标识变量通过下面一个箭头按钮转移到按钮右侧的“Label Cases by:”下面的矩形框中。
如果不使用系统默认值,或由于参与分析的变量量纲不一致需要指定选择项,则应该根据需要有选择性地执行下述某些步骤。
1.确定聚类方法
在主对话框中,点击“Methed”按钮,展开分层聚类分析的方法选择对话框,即“Hierachical Cluster Analysis:Method”。
在对话框中根据需要指定聚类方法、距离测度的方法、对数值进行转换方法,即标准化数值的方法和对测度的转换方法。
(1)聚类方法选择
“C1uster Method:”表中列出可以选择的聚类方法:
Between-groups linkage组内连接
Within-groups linkage组内连接
Nearest neighbor最近邻法
Furthest neighbor最远邻法
Centroid clustering重心聚类法
Median clustering中位数法
Ward’s method Ward最小方差法。
(后三种聚类方法应与欧氏距离平方法一起使用)
几种方法的具体情况见下面的英文文档
(2)对距离的测度方法选择
在Method中指定的是用哪两点间的距离的大小决定是否合并两类。距离的具体计算方法还根据参与距离的变量类型从以下三种对话框选择其一,展开选择菜单后再进行具体方法的选择。这三个对话框分别对应于等间隔测度的变量(一般为连续变量)、计数变量(一般为离散变量)和二值变量。这里只考虑连续变量的情况
“Interval”(系统默认)
Euclidean distance:Euclidean距离,即两观察单位间的距离为其值差的平方和的平方根,该技术用于Q型聚类;
Squared Euclidean distance:Euclidean距离平方,即两观察单位间的距离为其值差的平方和,该技术用于Q型聚类;
Cosine:变量矢量的余弦,这是模型相似性的度量;
Pearson correlation:相关系数距离,适用于R型聚类;
Chebychev:Chebychev距离,即两观察单位间的距离为其任意变量的最大绝对差值,该技术用于Q型聚类;
Block:City-Block或Manhattan距离,即两观察单位间的距离为其值差的绝对值和,适用于Q型聚类;
Minkowski:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的平方根;p由用户指定
Customized:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的第r次根,p与r由用户指定。
(3)确定标准化的方法:“Transform Value”
“Standardize” 下为标准化列表
对数据进行标准化的可选择的方法有:
① None 不进行标准化,是系统默认值。
② Z scores 把数值标准化到Z分数。
③ Range -1to l把数值标准化到-1到+l范围内。选择该项,对每个值用变量或观测量的值的范围去除。如果值范围是0,所有值保持不变。
④ Maximum magnituds of 1 把数值标准化到最大值为1。该方法是把正在标准化的变量或观测量的值用最大值去除。如果最大值为0,则改用最小值去除,其商加1。
⑤ Range 0 to 1 把数值标准化到0到1的范围内,对正在被标准化的变量或观测量的值剪去最小值,然后除以范围。如果范围是0,对变量或观测量的所有值都设置成0.5。
⑥ Mean of 1 把数值标准化到一个均值的范围内,对正在被标准化的变量或观测量的值除以这些值的均值。如果均值是0,对变量或观测量的所有值都加1,使其均值为1。
⑦ Standard deviation of 1 把数值标准化到单位标准差。该方法对正在被标准化的变量或观测量的值除以这些值的标准差,如果标准差为0,则这些值保持不变。
(4)测度的转换方法选择
对距离测度数值进行转换,在距离计算完成后进行。可选择的转换方法有三种,在“Methd”对话框右下角的标有“Transform Mearure”的框中选择。
① Absolute Values 把距离值标准化。当数值符号表示相关方向,且只对负相关关系感兴趣时使用此方法进行变换。
② Change sign 把相似性值变为不相似性值,或相反。用求反的方法使距离顺序颠倒。
③ Rescale to 0-- 1 range 通过首先去掉最小值然后除以范围的方法使距离标准化。对于已经按某种换算方法标准化了的测度,一般不再使用此方法进行转换。
2.选择要求输出的统计量:Statistics对话框
Aggomeration schedule 输出聚合过程表
Proximity matrix:输出的是每个案例之间的欧氏距离平方表(Q型聚类)。
Cluster membership决定聚合的群数。试探性地做时就选none,做完后根据判断的合适的群数在输入确定的群数,这时会得出一个更多的结果cluster membership,即在此群数下,各案例所属的群。当然也可选择Range of solutions确定群数的范围。
3.选择统计图表: Plot
Dendrogram 树形图;
Icicle冰柱图:
对于生成什么样的冰柱图还可以进一步用以下选择项确定:
All clusters 聚类的每一步都表现在图中。可用此种图查看聚类的全过程。但如果参与聚类的个体很多会造成图过大,没有必要。可以使用下面一个选择项限定显示的范围。
Specified range of clusters 指定显示的聚类范围。当选择此项时,该项下面的选择框加亮,表示等待输入显示范围。在Start后的矩形框中输入要求显示聚类过程的起始步数,在Stop后的矩形框中输入显示中止于哪一步,把显示的两步之间的增量输入到By后面的矩形框中。输入到矩形框中的数字必须是正整数。
例如,输入的结果是:Start: 3 Stop: 10 By:2
生成的冰柱图从第三步开始,显示第三、五、七、九步聚类的情况。
None:不生成冰柱图
对于显示方向可以用Orientation下面的选择项确定:
Vertical纵向显示的冰柱图。(系统默认)
HoriZontal显示水平的冰柱图。
4.生成新变量的选择:save
聚类分析的结果可以用新变量保存在工作数据文件中。单击主对话框的“save”按钮,展开相应的对话框。可以看出只能生成一个表明参与聚类的个体最终被分配到哪一类的新变量。通过对话框可以选择是否建立新变量和建立的新变量含义。
None 不建立新变量。
Single solution:单一结果。生成一个新变量表明每个个体聚类最后所属的类。在该项后面的矩形框中指定类数。如果指定5 clusters,则新变量的值为1-- 5。
Range of solutions:指定范围内的结果。生成若干个新变量,表明聚为若干个类时,每个个体聚类后所属的类。在该项后商的矩形框中指定显示范围,即把表示从第几类显示到第几类的数字分别输入到From后面的矩形框和through后面的矩形框中。例如输入结果是“From 4 through 6”,在聚类结束后在数据窗中原变量后面增加了3个新变量分别表明分为4类时、分为5类时和分为6类时的聚类结果。即聚为4、5、6类时各观测量分别属于哪一类。
新变量选择完成后按“Continue”按钮,返回到主对话框。
(二)迭代聚类
Analyze--> C1assify--> K-Means Cluster
“Methed”框,给出两个可选择的聚类方法:
1)Iterate and classify 选择初始类中心,在迭代过程中使用k-Means算法不断更换类中心,把观测量分派到与之最近的以类中心为标志的类中去;
2)Classify only 只使用初始类中心对观测量进行分类。
Number of clusters输入通过层次聚类或其他方式得出的聚类的合适的层数。
“Cluster Centers” 对话框有两项:
1)选择Read initial from 要求使用指定数据文件中的观测量作为初始类中心。选择此项单击鼠标键后,再按其后的“Flle”按钮,显示选择文件的对话框,指定文件所在位置(路径)和文件名。按“OK”按钮返回。在“Center”选择框中的“fi1e”按钮后面显示文件全名(包括路径)。
2)选择Write final as 要求把聚类结果中的各类中心数据保存到指定的文件中。操作方法与上相似。
save对话框中有两项:
1)选择Cluster Membership 建立一个新变量,系统默认变量名为那qc1_1。其值表示聚类结果,即各观测量被分配到哪一类。其值为1、2、3...的序号。该变量存人输入数据文件(New Data窗中)。
2)选择Distance from cluster center 建立一个新变量。系统默认变量名为那qc1_2。聚类结束后把各观测量距所属类中心间的欧氏距离存入输入数据文件(数据窗中)。
Iterate对话框:
设置迭代参数的对话框。如果选择了“Iterate and classify”方法进行聚类,还可以进一步选择迭代参数。
1)Maximum Iterations:限定K-Means算法中的迭代次数。改变后面框中的数字,则改变迭代次数。当达到限定的迭代次数时迭代停止。系统默认值为10。
2)Convergence Criterion:指定聚类判据。其值必须大于0,小于1。系统默认值为0.02。即当两次迭代计算的最小的类中心的变化距离小于初始类中心距离的百分之二时迭代停止。
3) Use Running means 选择此项,限定在每个观测量被分配到一类后即刻计算新的类中心。如果不选择此项,则在完成了所有观测量的一次分配后再计算各类的类中心。不选择此项会节省迭代时间。
Option对话框:输出统计量的选择项与缺失值处理
在Statitstacs组中可以选择要求计算和输出的统计量有:
Initia1 c1uster centers初始类中心
ANOVA table 方差分析表
C1uster information for each case每个观测量的分类信息。如分配到哪一类和该观测量距所属类中心的距离。
以上三项可以选择其中几项,也可以全选。
在Missing Va1ues组中选择一种处理带有缺失值观测量的方法,共有两种选择:
1)Exclude cases listwise将带有缺失值的观测量从分析中剔除。
2)Exclude cases pairwise只有当一个观测量的全部聚类变量值缺失时才将其从分析中剔除。否则根据其它非缺失变量值把它分配到最近的一类中去。
其它有用的使用:
1)筛减cases:
因为聚类分析计算的速度相对比较慢,而且如果case太多,结果也难于解释。有时可以将庞大的样本中进行随机筛选,取出小样本,进行聚类分析。下面是一种方法:
data-->select cases,选中random sample of cases,点击sample 复选框,弹出一个新的选框。Approximately( )% of all cases。在括号里填入从所有样本中选取的案例百分比。然后ok。
另外,在unselected cases are选框下有两种选择,filtered并不从原数据中将没有选中的case删除,只是“过滤”掉了;
deleted则是删掉了,然后形成一个新的数据。
2)求“群重心”的步骤:
之前须先将聚类结果保存在了原数据中。这里设保存的结果列命名为“cluster-3”.
Analyse-->compare means-->means
Dependant list选入准备参与比较的聚类变量和非聚类变量。Independant list选入保存的聚类结果“cluster-3”。
Option复选框,cell statistics选入mean,然后continue,ok.
3)使用k-means 确定初始群重心时,
centers-->initial from format选定,未知的在于file的格式。简介如下:
第一列:表示分成的群组数,如1、2、3…
以后各列为各聚类变量,注意与所在群组相对应。如果实在搞不定,可以先不选择initial from format,而选下面的write final as,呵呵,知道什么意思吗,先试一下,以确定正确的格式,再把数据替换一下就可以了。
转载请注明出处51数据库 » spss软件绘图教程视频 如何用spss画图
