
 黄泉路上祭家驹
黄泉路上祭家驹
1、易维护
采用面向对象思想设计的结构,可读性高,由于继承的存在,即使改变需求,那么维护也只是在局部模块,所以维护起来是非常方便和较低成本的。
2、质量高
在设计时,可重用现有的,在以前的项目的领域中已被测试过的类使系统满足业务需求并具有较高的质量。
3、效率高
在软件开发时,根据设计的需要对现实世界的事物进行抽象,产生类。使用这样的方法解决问题,接近于日常生活和自然的思考方式,势必提高软件开发的效率和质量。
4、易扩展
由于继承、封装、多态的特性,自然设计出高内聚、低耦合的系统结构,使得系统更灵活、更容易扩展,而且成本较低。
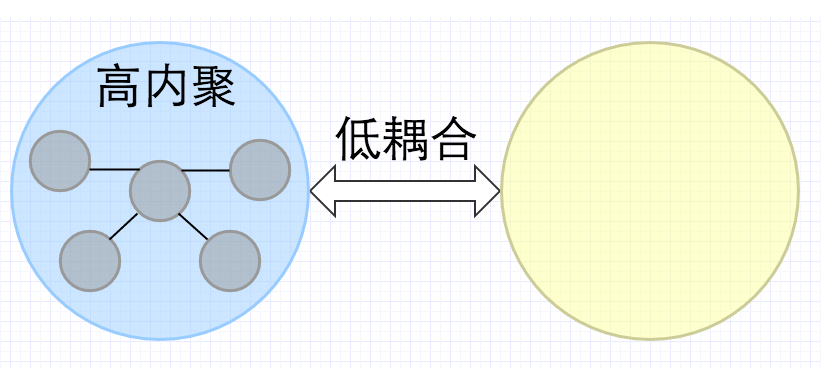
高内聚、低耦合的含义是什么?如何提高代码的可重用性?
百科粘过来的,你看看:
基本解释
高内聚低耦合,是软件工程中的概念,是判断设计好坏的标准,主要是面向对象的设计,主要是看类的内聚性是否高,耦合度是否低。
高内聚
内聚就是一个模块内各个元素彼此结合的紧密程度,高内聚就是一个模块内各个元素彼此结合的紧密程度高。 所谓高内聚是指一个软件模块是由相关性很强的代码组成,只负责一项任务,也就是常说的单一责任原则。
低耦合
耦合:一个软件结构内不同模块之间互连程度的度量(耦合性也叫块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差,模块间耦合的高低取决于模块间接口的复杂性,调用的方式以及传递的信息。) 对于低耦合,粗浅的理解是: 一个完整的系统,模块与模块之间,尽可能的使其独立存在。 也就是说,让每个模块,尽可能的独立完成某个特定的子功能。 模块与模块之间的接口,尽量的少而简单。 如果某两个模块间的关系比较复杂的话,最好首先考虑进一步的模块划分。 这样有利于修改和组合。[1]
编辑本段为什么要追求高内聚和低耦合
软件架构设计的目的简单说就是在保持软件内在联系的前提下,分解软件系统,降低软件系统开发的复杂性,而分解软件系统的基本方法无外乎分层和分割。但是在保持软件内在联系的前提下,如何分层分割系统,分层分割到什么样的粒度,并不是一件容易的事,这方面有各种各样的分解方法,比如:关注点分离,面向方面,面向对象,面向接口,面向服务,依赖注入,以及各种各样的设计原则等,而所有这些方法都基于高内聚,低耦合的原则。 高内聚和低耦合是相互矛盾的,分解粒度越粗的系统耦合性越低,分解粒度越细的系统内聚性越高,过度低耦合的软件系统,软件模块内部不可能高内聚,而过度高内聚的软件模块之间必然是高度依赖的,因此如何兼顾高内聚和低耦合是软件架构师功力的体现。 高内聚,低耦合的系统有什么好处呢?事实上,短期来看,并没有很明显的好处,甚至短期内会影响系统的开发进度,因为高内聚,低耦合的系统对开发设计人员提出了更高的要求。高内聚,低耦合的好处体现在系统持续发展的过程中,高内聚,低耦合的系统具有更好的重用性,维护性,扩展性,可以更高效的完成系统的维护开发,持续的支持业务的发展,而不会成为业务发展的障碍。[2]
使用数据库系统的优点和缺点是什么
一、关系数据库系统的优点
a.灵活性和建库的简单性:从软件开发的前景来看,用户与关系数据库编程之间的接口是灵活与友好的。目前在多数RDDMS产品中使用标准查询语言SQL,允许用户几乎毫无差别地从一个产品到另一个产品存取信息。与关系数据库接口的应用软件具有相似的程序访问机制,提供大量标准的数据存取方法。
b.结构简单:从数据建模的前景看,关系数据库具有相当简单的结构(元组),可为用户或程序提供多个复杂的视图。数据库设计和规范化过程也简单易行和易于理解。由于关系数据库的强有力的、多方面的功能,已经有效地支持许多数据库纳应用。
二、关系数据库系统的缺点
a.数据类型表达能力差:从下一代应用软件的发展角度来看,关系数据库的根本缺陷在于缺乏直接构造与这些应用有关的信息的类型表达能力,缺乏这种能力将产生以下有害的影响,例如:大多数RDBMS产品所采用的简单类型在重构复杂数据的过程中将会出现性能问题;数据库设计过程中的额外复杂性;RDBMS产品和编程语言在数据类型方面的不协调。
大多数现代的RDBMS产品已成熟地用于商务和财政方面,而这些领域不要求很高和很复杂的数据模型。虽然这些产品多多少少克服了一些以上所述的缺点,但从理论上看关系数据模型不直接支持复杂的数据类型,这是由于第一范式的要求,所有的数据必须转换为简单的类型,如整数、实数、双精度数和字符串。
对于工程应用来说,这种不能支持复杂数据类型的典型结果就是需要额外地分解数据结构工作,这些被分解的结构不能直接表示应用数据,且从基本成分重构时也非常繁琐和费时间。
b.复杂查询功能差:关系数据库系统的某些优点也同时是它的不足之处。虽然SQL语言为数据查询提供了很好的定义方法,但当用于复杂信息的查询时可能是非常繁琐的。此外,在工程应用时规范化的过程通常会产生大量的简单表。在这种环境下由存取信息产生的查询必须处理大量的表和复杂的码联系以及连接运算。
除非这些查询以固定的例行程序方式提供,否则用户就必须对SQL非常熟悉,以便适当地浏览数据库,查出所需的信息。然而,一旦查询方式按固定例行程序方式进行,用户最终就进行应用软件的常规维护。但应用或人机接口软件的变化又可能要求经常修改例行的查询,数据库结构的变化也可能导致例行查询程序以及应用或人机接口软件的失效。由于这些原因,关系数据库系统的维护开销可能是很大的。
由于关系数据库不能提供足够的构造能力及性能方面的原因,在进行较复杂的数据库设计过程中,不可能将许多工程问题直接分解成一些简单的部分。由于缺乏直接指针存取方法,所以查询有关的信息需要花费时间。
c.支持长事务能力差;由于RDBMS记录锁机制的颗粒度限制,对于支持多种记录类型的大段数据的登记和检查来说,简单的记录级的锁机制是不够的,但基于键值关系的较复杂的锁机制来说却很难推广也难以实现。
d.环境应变能力差:在要求系统频繁改变的环境下,关系系统的成本高且修改困难。在工程应用中支持"模式演变"(schema evolution)的功能是很重要的,而RDBMS不容易支持这种功能。另外,关系数据库和编程语言所提供的数据类型的不一致,使得从一个环境转换到另一个环境时需要多至30%的附加代码。
三、面向对象数据库系统的优点
a.能有效地表达客观世界和有效地查询信息:面向对象方法综合了在关系数据库中发展的全部工程原理、系统分析、软件工程和专家系统领域的内容。面向对象的方法符合一般人的思维规律、即将现实世界分解成明确的对象,这些对象具有属性和行为。系统设计人员用ODBMS创建的计算机模型能更直接反映客观世界,最终用户不管是否是计算机专业人员,都可以通过这些模型理解和评述数据库系统。
工程中的一些问题对关系数据库来说显得太复杂,不采取面向对象的方法很难实现。从构造复杂数据的前景看,信息不再需要手工地分解为细小的单元。ODBMS扩展了面向对象的编程环境,该环境可以支持高度复杂数据结构的直接建模。
b.可维护性好:在耦合性和内聚性方面,面向对象数据库的性能尤为突出。这使得数据库设计者可在尽可能少影响现存代码和数据的条件下修改数据库结构,在发现有不能适合原始模型的特殊情况下,能增加一些特殊的类来处理这些情况而不影响现存的数据。如果数据库的基本模式或设计发生变化,为与模式变化保持一致,数据库可以建立原对象的修改版本。这种先进的耦合性和内聚性也简化了在异种硬件平台的网络上的分布式数据库的运行。
c.能很好地解决"阻抗不匹配"(impedance mismatch)问题。面向对象数据库还解决了一个关系数据库运行中的典型问题:应用程序语言与数据库管理系统对数据类型支持的不一致问题,这一问题通常称之为阻抗不匹配问题。
四、面向对象数据库系统的缺点
a.技术还不成熟。面向对象数据库技术的根本缺点是这项技术还不成熟,还不广为人知。与许多新技术一样,风险就在于应用。从事面向对象数据库产品和编程环境的销售活动的公司还不令人信服,因为这些公司的历史还相当短暂,就该十几年前关系数据库的情况一样。ODBMS如今还存在着标准化问题,由于缺乏标准化,许多不同的ODBMS之间不能通用。此外,是否修改SQL以适应面向对象的程序,还是用新的对象查询语言来代替它,目前还没有解决,这些因素表明随着标准化的出现,ODBMS还会变化。
b.面向对象技术需要一定的训练时间:有面向对象系统开发经验的公司的专业人员认为,要成功地开发这种系统的关键是正规的训练,训练之所以重要是由于面向对象数据库的开发是从关系数据库和功能分解方法转化而来的,人们还需要学习一套新的开发方法使之与现有技术相结合。此外,面向对象系统开发的有关原理才刚开始具有雏形,还需一段时间在可靠性、成本等方面令人可接受。
c.理论还需完善:从正规的计算机科学方面看,还需要设计出坚实的演算或理论方法来支持ODBMS的产品。此外,既不存在一套数据库设计方法学,也没有关于面向对象分析的一套清晰的概念模型,怎样设计独立于物理存储的信息还不明确。
面向对象数据库和关系数据库系统之间的争论不同于70年代关系数据库和网状数据库的争论,那时的争论是在同一主要领域(即商业事务应用)中究竟是谁代替谁的问题。现在是肯定关系数据库系统基本适合商业事务处理的前提下,对非传统的应用,特别是工程中的应用用面向对象数据库来补充不足的问题。面向对象数据库系统将成为下一代数据库的典型代表,并和关系数据库系统并存(而不是替代)。它将在不同的应用领域支持不同的应用需求。
在JAVA编程中什么叫耦合
耦合性是编程中的一个判断代码模块构成质量的属性,不影响已有功能,但影响未来拓展,与之对应的是内聚性。
耦合性:也称块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。模块间耦合高低取决于模块间接口的复杂性、调用的方式及传递的信息。
内聚性:又称块内联系。指模块的功能强度的度量,即一个模块内部各个元素彼此结合的紧密程度的度量。若一个模块内各元素(语名之间、程序段之间)联系的越紧密,则它的内聚性就越高。
因此,现代程序讲究高内聚低耦合,即将功能内聚在同一模块,模块与模块间尽可能独立,互相依赖低。没有绝对没有耦合的模块组,只有尽量降低互相之间的影响。使模块越独立越好。
引物设计的、软件有哪些?有什么优点和缺点?
引物设计相关软件!
NoePrimer 2.03 独特的引物设计软件
Primer Premier 6.0 DEMO 序列分析与引物设计,非常棒的一个软件。
Oligo 7.36 Demo 引物设计分析著名软件,主要应用于核酸序列引物分析设计软件。
Primer D'Signer 1.1 免费的引物设计辅助软件,专门用于pASK-IBA和pPR-IBA表达载体,简化引物设计工作。
Array Designer 4.25 Demo DNA微阵列(microarray)软件,批量设计DNA和寡核苷酸引物工具。
Beacon Designer 7.80 Demo 实时荧光定量PCR分子信标(Molecular beacon )及TaqMan探针设计软件。
NetPrimer JAVA语言写成的免费引物设计软件,用IE打开运行。
TGGE-STAR DOS软件,PCR结合梯度凝胶电泳实验引物设计软件。
e-PCR 2.3.9 电子克隆是一种电脑软件,用来识别DNA序列标签位点(STSs)。
FastPCR 6.0.165b2 快速设计各种类型PCR引物,还包括一些常用的DNA与蛋白序列软件工具;
OligoMaster 1.0.164 多用户寡核苷酸管理软件,可建立寡核苷酸数据库
PerlPrimer v1.1.19 一个免费的用来设计引物的开源软件。
AmplifX 1.5.4 设计与管理引物的软件。
AutoDimer 1.0 快速筛选二聚体引物软件。
MutaPrimer 1.00 用于定点突变的引物设计桌面工具软件
ORFprimer 1.6.4.1 JAVA语言设计的引物设计软件
Primer Prim'er 5.6.0 Flash制作的PCR引物设计软件。
PCR Analyzer 1.0 实时RT-PCR反应中估算初始扩增子浓度软件
在线工具
DNAWorks 3.0 是一个帮助进行基因合成的设计寡核苷酸序列的免费程序。 程序仅需要输入一些简单的信息,比如,目标蛋白的氨基酸序列及合成核酸序列的温度。程序输出的为适合所选择生物表达的优化密码子的核酸序列。利用DNAWorks的帮助,用两步PCR法,可以成功合成长度达到3000碱基对的基因。原始网站。
The Primer Generator 在线引物设计程序。
Primer 3 比较有名的在线引物设计程序。
Primo Pro 3.4 在线PCR引物设计java系列软件。
Web Primer 斯坦福大学提供的在线引物设计软件。
AutoPrime 快速设计真核表达实时定量PCR引物在线软件 .
一般性引物自动搜索可采用“Premier Primer 5”软件,而引物的评价分析则可采用“Oligo 6”软件。
附上两款软件使用方法!
Primer Premier 5.0 的使用技巧简介
1. 功能
“Premier”的主要功能分四大块,其中有三种功能比较常用,即引物设计( )、限制性内切酶位点分析( )和DNA 基元(motif)查找( )。“Premier”还具有同源性分析功能( ),但并非其特长,在此略过。此外,该软件还有一些特殊功能,其中最重要的是设计简并引物,另外还有序列“朗读”、DNA 与蛋白序列的互换( )、语音提示键盘输入( )等等。
有时需要根据一段氨基酸序列反推到DNA 来设计引物,由于大多数氨基酸(20 种常见结构氨基酸中的18 种)的遗传密码不只一种,因此,由氨基酸序列反推DNA 序列时,会遇到部分碱基的不确定性。这样设计并合成的引物实际上是多个序列的混和物,它们的序列组成大部分相同,但在某些位点有所变化,称之为简并引物。遗传密码规则因物种或细胞亚结构的不同而异,比如在线粒体内的遗传密码与细胞核是不一样的。“Premier”可以针对模板DNA 的来源以相应的遗传密码规则转换DNA 和氨基酸序列。软件共给出八种生物亚结构的不同遗传密码规则供用户选择,有纤毛虫大核(Ciliate Macronuclear)、无脊椎动物线粒体(Invertebrate Mitochondrion)、支原体(Mycoplasma)、植物线粒体(Plant Mitochondrion)、原生动物线粒体(Protozoan Mitochondrion)、一般标准(Standard)、脊椎动物线粒体(Vertebrate Mitochondrion)和酵母线粒体(Yeast Mitochondrion)。
2. 使用步骤及技巧
“Premier”软件启动界面如下:
(转载的时候就没有图)
其主要功能在主界面上一目了然(按钮功能如上述)。限制性酶切点分析及基元查找功能比较简单,点击该功能按钮后,选择相应的限制性内切酶或基元(如-10 序列,-35 序列等),按确定即可。常见的限制性内切酶和基元一般都可以找到。你还可以编辑或者添加新限制性内切酶或基元。
进行引物设计时,点击按钮,界面如下:
进一步点击按钮,出现“search criteria”窗口,有多种参数可以调整。搜索目的(Seach For)有三种选项,PCR 引物(PCR Primers),测序引物(Sequencing Primers),杂交****(Hybridization Probes)。搜索类型(Search Type)可选择分别或同时查找上、下游引物(Sense/Anti-sense Primer,或Both),或者成对查找(Pairs),或者分别以适合上、下游引物为主(Compatible with Sense/Anti-sense Primer)。另外还可改变选择区域(Search Ranges),引物长度(Primer Length),选择方式(Search Mode),参数选择(Search Parameters)等等。使用者可根据自己的需要设定各项参数。如果没有特殊要求,建议使用默认设置。然
后按,随之出现的Search Progress 窗口中显示Search Completed 时,再按,这时搜索结果以表格的形式出现,有三种显示方式,上游引物(Sense),下游引物(Anti-sense),成对显示(Pairs)。默认显示为成对方式,并按优劣次序(Rating)排列,满分为100,即各指标基本都能达标(如下图)。
点击其中一对引物,如第1#引物,并把上述窗口挪开或退出,显示“Peimer Premier”主窗口,如图所示:
该图分三部分,最上面是图示PCR 模板及产物位置,中间是所选的上下游引物的一些性质,最下面是四种重要指标的分析,包括发夹结构(Hairpin),二聚体(Dimer),错误引发情况(False Priming),及上下游引物之间二聚体形成情况(Cross Dimer)。当所分析的引物有这四种结构的形成可能时,按钮由变成,点击该按钮,在左下角的窗口中就会出现该结构的形成情况。一对理想的引物应当不存在任何一种上述结构,因此最好的情况是最下面的分析栏没有,只有。值得注意的是中间一栏的末尾给出该引物的最佳退火温度,可参考应用。
在需要对引物进行修饰编辑时,如在5’端加入酶切位点,可点击,然后修改引物序列。若要回到搜索结果中,则点击按钮。如果要设计简并引物,只需根据源氨基酸序列的物种来源选择前述的八种遗传密码规则,反推至DNA 序列即可。对简并引物的分析不需像一般引物那样严格。总之,“Premier”有优秀的引物自动搜索功能,同时可进行部分指标的分析,而且容易 使用,是一个相当不错的软件。
Oligo 6.22 使用技巧简介
1. 功能
在专门的引物设计软件中,“Oligo”是最著名的。它的使用并不十分复杂,但初学者容易被其复杂的图表吓倒。Oligo 5.0 的初始界面是两个图:Tm 图和ΔG 图;Oligo 6.22 的界面更复杂,出现三个图,加了个Frq 图。“Oligo”的功能比“Premier”还要单一,就是引物设计。但它的引物分析功能如此强大以至于能风靡全世界。
2. 使用(以Oligo 6.22 为例)
Oligo 6.22 的启动界面如下:
图中显示的三个指标分别为Tm、ΔG 和Frq,其中Frq 是6.22 版本的新功能,为邻近6至7 个碱基组成的亚单位在一个指定数据库文件中的出现频率。该频率高则可增加错误引发的可能性。因为分析要涉及多个指标,起动窗口的cascade 排列方式不太方便,可从windows菜单改为tili 方式。如果觉得太拥挤,可去掉一个指标,如Frq,这样界面的结构同于Oligo5.0,只是显示更清楚了。
经过Windows/Tili 项后的显示如图:
在设计时,可依据图上三种指标的信息选取序列,如果觉得合适,可点击Tm 图块上左下角的Upper 按钮,选好上游引物,此时该按钮变成,表示上游引物已选取好。下游引物的选取步骤基本同上,只是按钮变成Lower。∆G 值反映了序列与模板的结合强度,最好引物的∆G 值在5’端和中间值比较高,而在3’端相对低(如图:)
Tm 值曲线以选取72℃附近为佳,5’到3’的下降形状也有利于引物引发聚合反应。Frq 曲线为“Oligo 6”新引进的一个指标,揭示了序列片段存在的重复机率大小。选取引物时,宜选用3’端Frq 值相对较低的片段。
当上下游引物全选好以后,需要对引物进行评价并根据评价对引物进行修改。首先检查引物二聚体尤其是3’端二聚体形成的可能性。需要注意的是,引物二聚体有可能是上游或下游引物自身形成,也有可能是在上下游引物之间形成(cross dimer)。二聚体形成的能值越高,越不符合要求。一般的检测(非克隆)性PCR,对引物位置、产物大小要求较低,因而应尽可能选取不形成二聚体或其能值较低的引物。第二项检查是发夹结构(hairpin);与二聚体相同,发夹结构的能值越低越好。一般来说,这两项结构的能值以不超过4.5 为好。
当然,在设计克隆目的的PCR 引物时,引物两端一般都添加酶切位点,必然存在发夹结构,而且能值不会太低。这种PCR 需要通过灵活调控退火温度以达到最好效果,对引物的发夹结构的检测就不应要求太高。第三项检查为GC 含量,以45-55%为宜。有一些模板本身的GC 含量偏低或偏高,导致引物的GC 含量不能被控制在上述范围内,这时应尽量使上下游引物的GC 含量以及Tm 值保持接近,以有利于退火温度的选择。如果PCR 的模板不是基因组DNA,而是一个特定模板序列,那么最好还进行False priming site 的检测。这项检查
可以看出引物在非目的位点引发PCR 反应的可能性。如果引物在错配位点的引发效率比较高,就可能出假阳性的PCR 结果。一般在错配引发效率以不超过100 为好,但对于特定的模板序列,还应结合比较其在正确位点的引发效率。如果两者相差很大,比如在正确位点的引发效率为450 以上,而在错误位点的引发效率为130,那么这对引物也是可以接受的。当我们结束以上四项检测,按Alt+P 键弹出PCR 窗口,其中总结性地显示该引物的位置、产物大小、Tm 值等参数,最有用的是还给出了推荐的最佳退火温度和简单的评价。
由于“Oligo”软件的引物自动搜索功能与“Primer Premier 5”的相类似,并且似乎并不比后者更好用,在此不再赘述。其实,使用软件自动搜索引物就是让计算机按照人的要求去寻找最佳引物,如果参数设置得当将大大提高工作效率。
除了本地引物设计软件之外,现在还有一些网上引物设计软件,如由Whitehead Institute开发的“Primer 3”等(本网站http://210.72.11.60/ 已引进并调试好该软件,欢迎使用)。该软件的独特之处在于,对全基因组PCR 的引物设计;可以将设计好的引物对后台核酸数据库进行比对,发现并排除可引发错配的引物。因此建议经常做全基因组PCR 的用户试用。
什么是高耦合低内聚?
高耦合低内聚:块间联系高,块内联系低。
其中内聚是从功能角度来度量模块内的联系,一个好的内聚模块应当恰好做一件事。它描述的是模块内的功能联系。
而耦合是软件结构中各模块之间相互连接的一种度量,耦合强弱取决于模块间接口的复杂程度、进入或访问一个模块的点以及通过接口的数据。
高内聚低耦合,是软件工程中的概念,是判断设计好坏的标准,主要是面向对象的设计,主要是看类的内聚性是否高,耦合度是否低。
扩展资料:
程序开发中的低耦合高内聚
模块之间联系越紧密,其耦合性就越强,模块之间越独立则越差,模块间耦合的高低取决于模块间接口的复杂性,调用的方式以及传递的信息。
形象的说,就是要将代码写的和电脑一样,主类就是电脑的主机箱,当程序需要实现什么功能的时候只需要加其他的类引入接口,就像电脑上的usb接口。
一个完整的系统,模块与模块之间,尽可能的使其独立存在。也就是说,让每个模块,尽可能的独立完成某个特定的子功能。
模块与模块之间的接口,尽量的少而简单。如果某两个模块间的关系比较复杂的话,最好首先考虑进一步的模块划分。这样有利于修改和组合。
在程序开发中,尽量做到低耦合高内聚,这样程序的维护成本以及可读性也会大大增强。
参考资料来源:百度百科-高内聚低耦合
什么是分布式系统架构
分布式应用程序就是指应用程序分布在不同计算机上,通过网络来共同完成一项任务,通常为服务器/客户端模式。更广义上理解“分布”,不只是应用程序,还包括数据库等,分布在不同计算机,完成同一个任务。之所以要把一个应用程序分布在不同的计算机上,主要有两个目的:
1) 分散服务器的压力
大型系统中,模块众多,并发量大,仅用一个服务器承载往往会发生压力过大而导致系统瘫痪的情况。可以在横向和纵向两方面来进行拆分,把这些模块部署到不同的服务器上。这样整个系统的压力就分布到了不同的服务器上。
l 横向:按功能划分。
l 纵向:N层架构,其中的一些层分布到不同的服务器上(分层的概念会在后文进行介绍)。
2) 提供服务,功能重用
使用服务进行功能重用比使用组件进行代码重用更进一层。举例来说,如果在一个系统中的三个模块都需要用到报表功能,一种方法是把报表功能做成一个单独的组件,然后让三个模块都引用这个组件,计算操作由三个模块各自进行;另一种方法是把报表功能做成单独的服务,让这三个模块直接使用这个服务来获取数据,所有的计算操作都在一处进行,很明显后者的方案会比前者好得多。
服务不仅能对内提供还能对外提供,如果其他合作伙伴需要使用我们的报表服务,我们又不想直接把所有的信息都公开给它们。在这种情况下组件方式就不是很合理了,通过公开服务并对服务的使用方做授权和验证,那么我们既能保证合作伙伴能得到他们需要的数据,又能保证核心的数据不公开。
面向对象程序设计语言有哪些?
1、Smalltalk
Smalltalk被公认为历史上第二个面向对象的程序设计语言和第一个真正的集成开发环境(IDE)。由Alan Kay,Dan Ingalls,Ted Kaehler,Adele Goldberg等于70年代初在Xerox PARC开发。
Smalltalk对其它众多的程序设计语言的产生起到了极大的推动作用,主要有:Objective-C,Actor, Java 和Ruby等。90年代的许多软件开发思想得利于Smalltalk,例如Design Patterns, Extreme Programming(XP)和Refactoring等。
2、Eiffel
Eiffel语言是继Smalltalk-80之后的另一个"纯"OOPL。这种语言是由OOP领域中著名的专家Bertrand Meyer等人20世纪80年代后期在ISE公司(Interactive Software Engineering Inc.)开发的,它的主要特点是全面的静态类型化、有大量的开发工具、支持多继承。
3、C++
C++是C语言的继承,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行以继承和多态为特点的面向对象的程序设计。
C++擅长面向对象程序设计的同时,还可以进行基于过程的程序设计,因而C++就适应的问题规模而论,大小由之。
4、Java
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。
Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程 。
Java具有简单性、面向对象、分布式、健壮性、安全性、平***立与可移植性、多线程、动态性等特点 。Java可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等 。

扩展资料:
面向对象设计的结果,既可以用面向对象语言实现,也可以用非面向对象语言实现。
面向对象程序设计语言本身就支持面向对象概念的实现,其编译程序可以自动地实现面向对象概念到目标程序的映射。而且与非面向对象语言相比,面向对象语言还具有以下一些优点:
(1)一致的表示方法。
面向对象的采用方法从问题域表示到面向对象分析,再到面向对象设计与实现始终稳定不变。一致的表示方法不但有利于在软件开发过程中始终使用统一的概念,也有利于维护人员理解软件的各种配置成分。
(2)可重用性。
为了能带来可观的商业利益.必须在更广泛的范围中运用重用机制,而不是仅仅在程序设计这个层次上进行重用。
软件开发组织既可能重用它在某个问题域内的OOA结果,也可能重用相应的OOD和OOP结果。
(3)可维护性。
在实际软件系统开发中,维护人员面对的主要是源程序,如果程序设计语言本身能显式地表达问题域语义,对维护人员理解所要维护的软件将有很大帮助。
因此,选择程序设计语言应该考虑的首要因素是,哪个程序设计语言能最好地表达问题域语义。一般来说,实现面向对象分析、设计的结果,应该尽量选用面向对象程序设计语言。
参考资料:
转载请注明出处51数据库 » 软件设计内聚性优点 面向对象程序设计的优点是什么
